10 AI Agent Cost Optimization Strategies for Budget Management

AI Agent Cost Optimization is a set of techniques that help reduce token, API, and infrastructure costs when operating AI Agents. This article presents the reasons for rapidly increasing costs, introduces 10 AI Agent Cost Optimization strategies, and provides a framework to balance cost and performance in real-world scenarios.
Key Takeaways
- Causes of Rising Costs: Identify factors causing budget increases, such as token fee disparities, context bloat, and tool-calling loops, to proactively control spending effectively.
- Optimization Strategies: Master 10 in-depth techniques like Dynamic Model Routing and Semantic Caching to significantly reduce API costs while maintaining stable output quality.
- Balanced Operational Framework: Approach a cost-performance coordination framework by task group, supporting the design of smart and resource-efficient AI systems.
- FAQ: Clarify cost optimization concepts and how to handle common LLM budget wastes to optimize practical operational workflows.
Why Do AI Agent Operational Costs Spiral Out of Control?
The cost of deploying an AI Agent with a token-based pricing model can rise very quickly if context usage, response length, and the system's tool-calling behavior are not carefully managed.
- Disparity Between Input and Output Tokens: Providers usually charge 3-4 times more for output tokens than input tokens because the text generation process is more resource-intensive. Overly long responses or redundant explanations will sharply increase both costs and latency.
- Context Window Bloat: Sending the entire conversation history or long documents in every request causes the input token count to grow over time. Each turn requires paying for the entire old context plus the new part, causing the cost per chat session to rise rapidly.
- Tool-calling Loops and API Overhead: An AI Agent may continuously recall an API or tool when encountering errors if retry limits are not set. This leads to prolonged tool-calling chains, exploding token volume and costs just to process a single unsuccessful task.
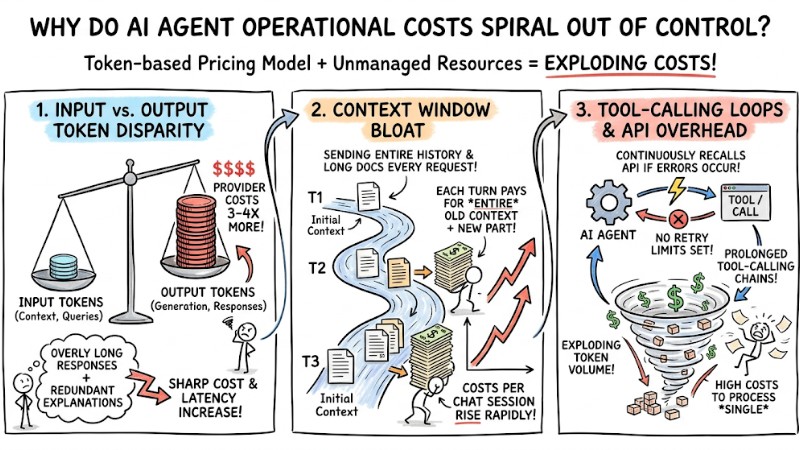
The cost of operating an AI agent can increase rapidly if context usage is not properly managed
10 Most Effective AI Agent Cost Optimization Strategies
Below are popular LLMOps techniques to reduce inference costs for AI Agents while keeping the result quality appropriate for each task type.
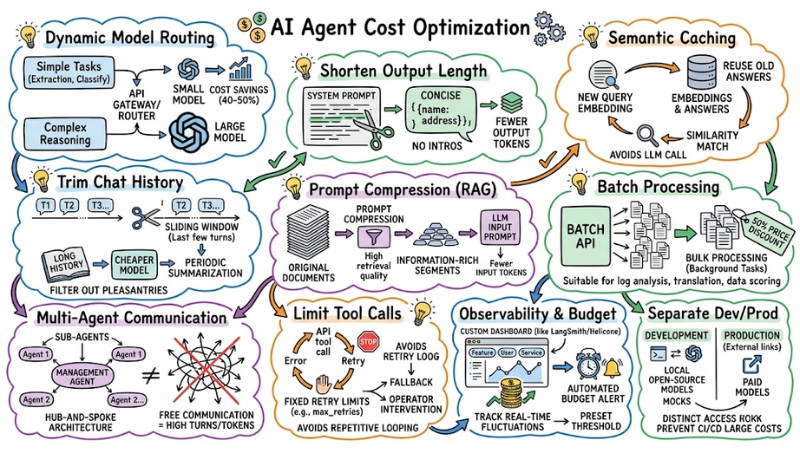
1. Apply Dynamic Model Routing Based on Task Complexity
Instead of always using high-end models, set up an API Gateway or router to classify complexity and direct queries to the appropriate model. Simple tasks like extraction, classification, or short translations can use small, low-cost models, while multi-step reasoning requests use larger models. This typically saves about 40-50% of overall costs.
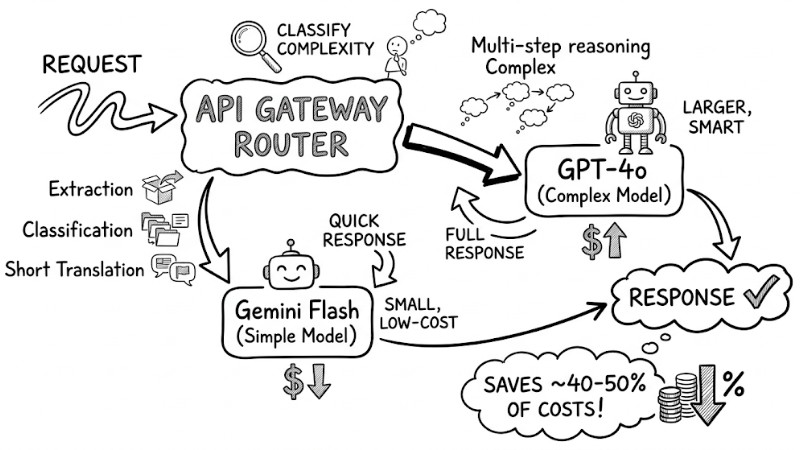
The request flow passes through the API Gateway Router, branching to the Simple Model and Complex Model
2. Shorten Output Length with Prompt Engineering
Since output tokens have a higher unit price, limit response length by clearly specifying a concise style in the system prompt, omitting greetings, and prioritizing data structures like JSON.
Optimal Prompt Example: "You are a data extraction tool. Only return a single JSON object containing 'name' and 'address'. Absolutely no explanatory text or introductory segments. Maximum output length: 50 words."
3. Implement Semantic Caching
Instead of only caching exact strings, store question embeddings in a vector database and look for new queries with high similarity to reuse old answers without recalling the LLM. This is particularly effective for systems with many similar questions, significantly reducing API calls and improving user latency.
# Basic Semantic Caching logic with Python
user_query = "How do I change my password?"
query_embedding = get_embedding(user_query)
# Check for similarity in Vector Database (e.g., Redis, Pinecone)
cached_response = vector_db.search_similar(query_embedding, threshold=0.95)
if cached_response:
return cached_response # Return immediately, zero LLM cost
else:
response = call_llm(user_query)
vector_db.save(query_embedding, response) # Cache for future use
return response
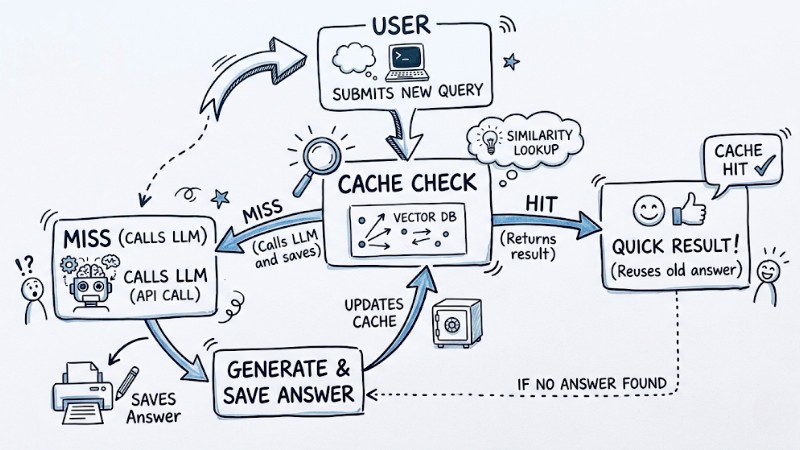
Semantic Caching workflow
4. Optimize Context Management and Trim Chat History
Context management should be based on a sliding window that only keeps the last few conversation turns. Combine this with periodic summarization of long history using a cheaper model. Additionally, filter out social pleasantries or irrelevant content before feeding it into the context to limit context window bloat.
5. Use Prompt Compression Techniques in RAG
When using Retrieval-Augmented Generation (RAG), instead of putting long original documents into the prompt, apply prompt compression to extract short, information-rich segments and remove less relevant parts. This improves retrieval quality and cuts input tokens significantly for each request.
6. Batch Processing
For tasks that do not require real-time responses, use the provider's Batch API to send many requests in one lot at a price usually about 50% lower than individual calls. This is suitable for background processing like log analysis, large-scale document translation, or data scoring.
7. Control Communication Frequency in Multi-Agent Orchestrators
In multi-agent systems, design a hub-and-spoke architecture with a central management Agent assigning tasks to sub-agents, rather than allowing agents to communicate freely. This model significantly reduces internal message turns and token consumption for unnecessary exchanges.
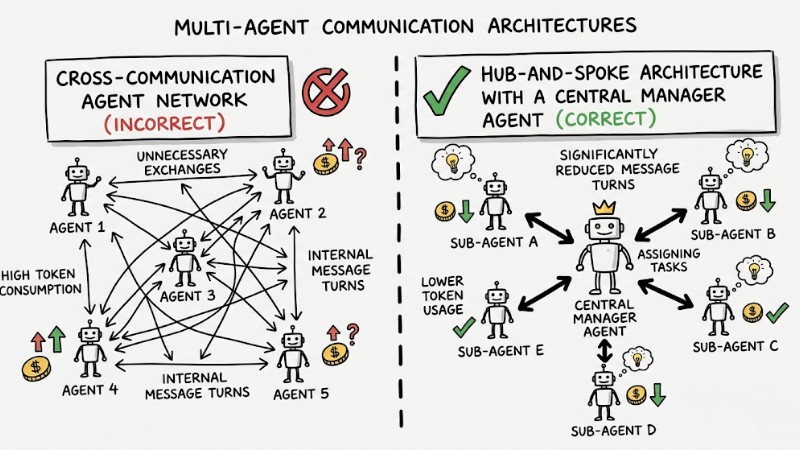
Cross-network Agent communication and Hub-and-Spoke architecture with central coordination
8. Limit Tool Calls and Reasoning Loops
Set a fixed threshold for tool retries or consecutive reasoning steps (e.g., limit max_retries or total steps per session) to avoid repetitive API calling during errors. When the threshold is exceeded, the system should stop, switch to a fallback, or request operator intervention.
9. Establish Observability and Automated Budget Alerts
Use cost monitoring platforms like LangSmith, Helicone, or custom dashboards to tag costs by feature, user, or service and track fluctuations in real-time. When a cost spike exceeds a preset threshold, the system can automatically send alerts and pause non-priority workflows.
10. Separate Development and Production Environments
In development and testing environments, prioritize using local open-source models or mock configurations instead of calling expensive commercial models directly. Only production environments should have access to paid models to prevent CI/CD or feature testing from incurring unintended large costs.
AI Agent Cost-Performance Balancing Framework
The goal is not to cut costs at any price but to design an operational framework where efficiency, quality, and cost are optimized simultaneously by task group.
- Prioritize Quality for High-Stakes Tasks: For tasks directly related to revenue, legal risk, or safety - such as financial advice, medical support, or critical source code generation - choose high-quality models, allow wide contexts, and more reasoning steps to achieve the highest acceptable accuracy and reliability.
- Force Lower Costs for High-Volume Queries: For repetitive high-volume tasks like mass content summarization, comment classification, or static data extraction, prioritize low-cost models, batch processing, and semantic caching to reduce the price per task while meeting minimum quality requirements.
- Monitor the "Success Rate" Metric: Any change intended to optimize costs, such as switching to a cheaper model or shortening prompts, must be measured by the success rate before and after the change, along with the cost per successful task. If costs drop sharply while the success rate remains acceptable, the configuration is maintained; if error rates rise significantly, restore or adjust the strategy.
FAQ
What is AI Agent Cost Optimization?
It is the process of measuring and applying techniques like choosing the right models, optimizing prompts, caching, and limiting usage to reduce AI Agent operational costs - specifically token and API costs - while maintaining acceptable quality for each task type.
What consumes the most money when operating an AI Agent?
The largest costs usually come from token generation (output) because output tokens have a higher unit price, combined with context overhead when sending long conversation history in every call. Additionally, infrastructure costs for vector databases and third-party APIs (like search or scraping) contribute significantly to the total budget.
Are agentic workflows actually more expensive than standard Single-prompt models?
Yes, because agentic workflows often break a request into multiple consecutive reasoning steps. Each step is an LLM call with context, so the total tokens consumed for one task can be many times higher than a single-prompt request. Without limiting steps or optimizing context, costs can increase by a very large multiple.
How do I know if I am wasting my LLM budget on the wrong model?
A common sign is using premium models to process fixed, rule-based tasks - like structured data extraction, simple classification, or JSON mapping - where the cost per task is significantly higher than the value provided. In these cases, test smaller or specialized extraction models and compare accuracy; if the difference is small but the cost drop is large, standardize the pipeline to the lighter model.
Read more:
- When to Use an AI Agent? 7 Signs You Need Automation
- What is a Coding Agent? The Best Automated AI Programming Solution
- 7 Practical Coding Agent Use Cases to Optimize Your Workflow
AI Agent Cost Optimization is not just about cutting API bills; it is a process of redesigning architecture, model routing, context management, and real-time cost tracking to use the right resources for the right job. By synchronously applying strategies like dynamic routing, semantic caching, batch processing, and guardrails for tool calls, you can significantly reduce inference costs while maintaining AI Agent performance at critical touchpoints with users.
Tags