What is Deep Learning? Applications, Future Trends, and Essential Knowledge

The shift from rule-based programming to a data-driven approach has completely changed how we build software systems. Faced with massive volumes of unstructured data like images, audio, or natural language, software engineers need a more powerful solution than traditional linear algorithms. This article will "dissect" the internal architecture and core mathematical mechanisms of Deep Learning to help you understand the operating principles behind the AI boom.
Key Takeaways
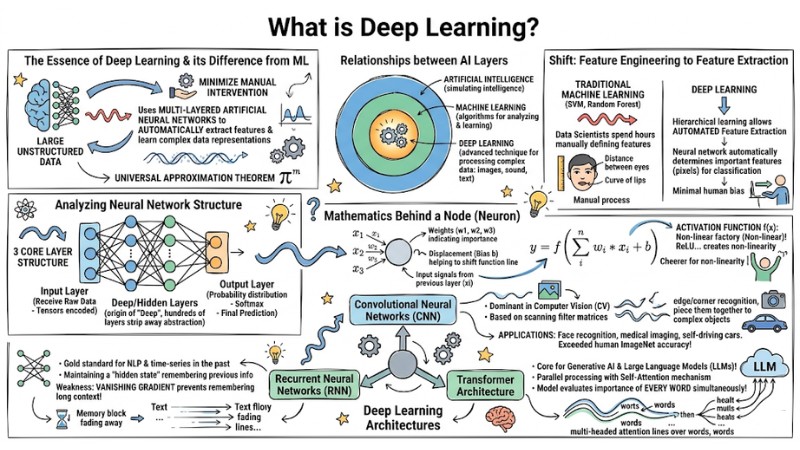
- Nature of Deep Learning: Clearly understand that Deep Learning is a subset of Machine Learning, using multi-layered neural networks to automatically extract features, completely removing the manual burden on humans compared to traditional ML.
- Mathematical Principles: Master the 3-layer structure (Input - Hidden - Output) and the vital role of Activation Functions like ReLU in creating non-linearity, helping neural networks learn complex rules.
- Self-Correction Mechanism: Deeply understand the Forward Pass process (to calculate Loss) and Backpropagation (using derivatives/Gradient Descent) to make the model gradually converge to accurate results.
- Architectures Shaping Technology: Differentiate specialized architectures: CNN (image processing), RNN (sequence processing - legacy), and Transformer (Self-Attention mechanism for parallel processing - the foundation of Generative AI).
- Real-world Challenges: Identify "bottlenecks" including massive GPU costs, Overfitting (rote learning), and the "Black Box" problem (difficulty interpreting decisions), which is particularly dangerous in healthcare and finance.
- Deployment Roadmap: Recommended 3 directions: Self-training (expensive/requires experts), Fine-tuning open models (specialized optimization), and API integration (safe/cost-effective option for businesses).
- FAQ Resolution: Clarify the difference between ML and DL, why powerful GPUs are needed, why Transformers dominate today, and how to manage security when connecting systems to large model APIs.
The Essence of Deep Learning and its Difference from Machine Learning
Definition of Deep Learning
Deep Learning is a branch of Machine Learning that uses multi-layered artificial neural networks to automatically extract features and learn complex data representations from large amounts of unstructured information, minimizing manual human intervention.
The nature of this method is based on the Universal Approximation Theorem, which proves that a neural network with sufficient depth and number of parameters is capable of simulating any continuous mathematical function.
Relationships between AI Layers
In the modern technology ecosystem, artificial intelligence is divided into inheriting layers. AI is the broadest concept covering all efforts to simulate intelligence. Machine Learning is a subset of AI, focusing on using algorithms to analyze data and learn. At the innermost core, we have Deep Learning, one of the most advanced techniques today for processing complex data types like images, sound, and text.
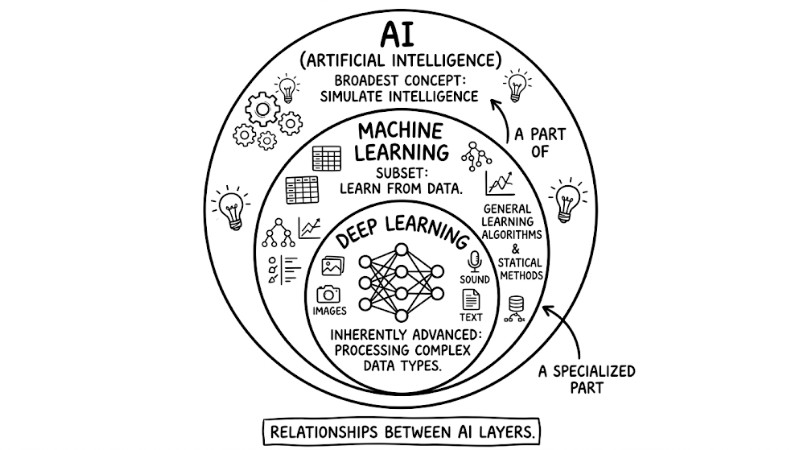
The relationship between AI layers
The Shift from Feature Engineering to Feature Extraction
The most core difference between traditional Machine Learning (such as SVM, Random Forest) and Deep Learning lies in the data flow processing. In Machine Learning, Data Scientists often spend a lot of time manually performing the feature extraction step (Feature Engineering). For example, for AI to recognize faces, engineers must program the computer to measure the distance between eyes or the curve of the lips.
In contrast, hierarchical learning architecture allows for complete automation of this step through the Feature Extraction mechanism. For instance, a neural network will automatically analyze millions of pixels and determine which features are most important for classification, minimizing human bias.
| Criteria | Machine Learning (ML) | Deep Learning (DL) |
|---|---|---|
| Data Features | Tabular, structured data. | Unstructured data (images, text, video). |
| Data Requirements | Works well with small/medium data volumes. | Requires massive Big Data to converge. |
| Feature Extraction | Engineers define manually (Feature Engineering). | System extracts automatically (Feature Extraction). |
| Hardware Required | Processes well on standard CPUs. | Mandatory high-performance GPU/TPU. |
| Interpretability | High (easy to understand decision logic). | Low (Black Box). |
Analyzing Artificial Neural Network Structure
The media often likens Artificial Neural Networks to the human brain. However, from an engineer's perspective, this system has no "consciousness"; its essence is millions of arithmetic matrix multiplications running in parallel.
3 Core Layer Structure
A standard Deep Neural Network (DNN) consists of three main components:
- Input Layer: Where raw data encoded into multi-dimensional structures (Tensors) is received.
- Hidden Layers: This is the origin of the word "Deep" in Deep Learning. Data passes through hundreds of hidden layers, each stripping away a different level of abstraction from the data.
- Output Layer: Contains probability distribution functions (like Softmax) to provide the final prediction result.
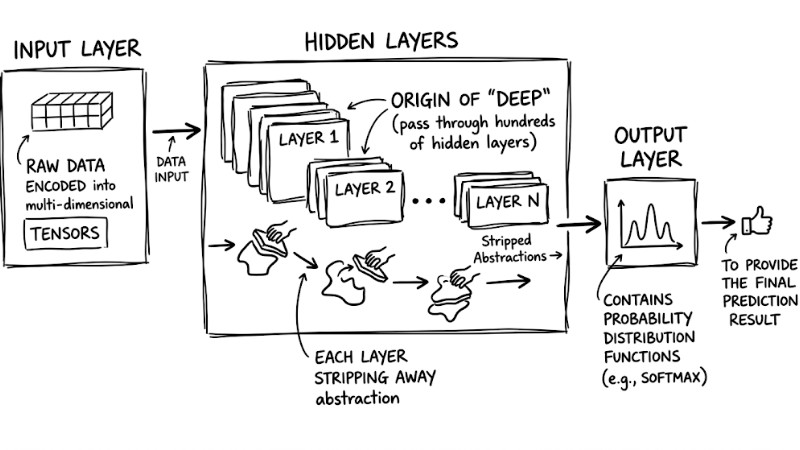
A multilayer neural network consists of three main components
Mathematics Behind a Node (Neuron)
Each artificial neuron (Node) in the network executes a simple yet powerful mathematical equation:
$$y = f\left(\sum_{i=1}^{n} (w_i \cdot x_i) + b\right)$$
Where:
- $x_i$: Input signals from the previous layer.
- Weight ($w_i$): Weights indicating the importance of the input signal.
- Bias ($b$): Displacement, helping to shift the function line to increase flexibility.
- Activation function $f(x)$: The vital factor creating non-linearity (Non-linear). Without an activation function like ReLU, the entire massive neural network would lose its non-linearity, becoming a simple and ineffective linear regression model.
Below is pseudocode illustrating this computation flow in Python:
import numpy as np
# Simulate a simple node (neuron)
inputs = np.array([1.5, 2.0, -0.5]) # Input data (1D Tensor)
weights = np.array([0.8, -0.2, 0.5]) # Weights
bias = 0.1 # Bias
# Calculate the weighted sum: Sum(w * x) + b
z = np.dot(inputs, weights) + bias
# ReLU activation function: f(z) = max(0, z)
# Eliminate negative values to introduce non-linearity
output = np.maximum(0, z)
print(f"Output after activation: {output}")
The Heart of the System: Forward Pass and Backpropagation
For a neural network to "learn," it needs a continuous self-correction mechanism. This cycle relies entirely on two data processing phases: Forward Propagation and Backpropagation.
Forward Pass and Loss Function
In the forward pass phase, data goes from the Input layer through the Hidden layers and generates a prediction at the Output layer. At this point, the system will compare the prediction result with the actual label through a Loss Function. This function measures the error: the higher the value, the more incorrect the model's prediction.
Backpropagation and Optimization
Once the output error is known, the Backpropagation algorithm is activated. By using the chain rule in calculus, the system calculates the partial derivative of the Loss Function with respect to each weight in the network from the last layer back to the first.
Then, the Gradient Descent algorithm updates all Weight values. You can imagine this process as finding a way down to the foot of a mountain in thick fog: each step is decided by feeling which direction the slope beneath your feet is leaning. Because billions of matrices must be multiplied simultaneously, this process requires powerful parallel computing architecture from GPUs.
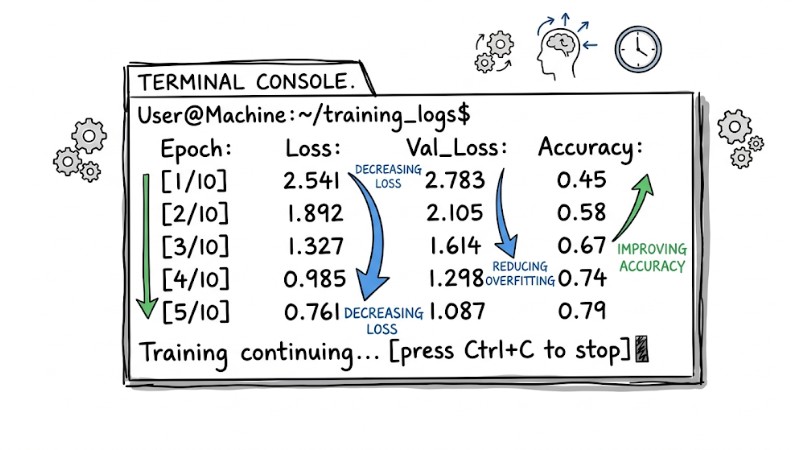
Terminal log of Gradient Descent training process
# Gradient Descent process updating Weights over Epochs
Epoch 1/50 - Loss: 2.5401 - Accuracy: 0.2310 # Network predicts poorly, high loss
Epoch 10/50 - Loss: 1.8320 - Accuracy: 0.4502 # Backpropagation starts updating weights
Epoch 25/50 - Loss: 0.9405 - Accuracy: 0.7250 # Model begins capturing data features
Epoch 50/50 - Loss: 0.1004 - Accuracy: 0.9850 # Successful convergence, reached the bottom of the gradient
Deep Learning Architectures Shaping the Tech World
Data science has developed specialized network architectures to handle different data formats.
Convolutional Neural Networks (CNN)
CNNs are the dominant architecture in the field of Computer Vision (CV). Based on the mechanism of scanning filter matrices across an image, CNNs can recognize local features like edges and corners, then piece them together to recognize complex objects.
- Applications: Face recognition, medical image diagnosis, self-driving cars.
- Milestone: Has exceeded human accuracy levels on the classic ImageNet dataset.
Recurrent Neural Networks (RNN)
In the past, RNNs were the gold standard for NLP tasks and time-series data. By maintaining a "hidden state," RNNs remember information from previous steps. However, it suffers from a fatal weakness called the vanishing gradient phenomenon, which prevents it from "remembering" context in very long text segments.
Transformer Architecture
The Transformer architecture processes data flow through the Self-Attention mechanism, allowing the model to evaluate the importance of every word in a sentence simultaneously (parallel processing) instead of reading word by word. This is the core architecture that created the era of Generative AI and Large Language Models (LLMs).
- Applications: Deep contextual translation, automatic text summarization, code generation.
- Strength: Unlimited scalability with trillions of parameters.
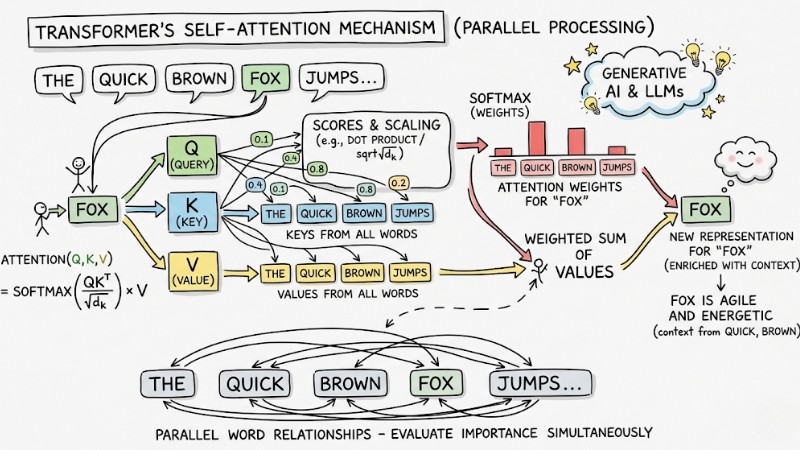
The Self-Attention Mechanism of the Transformer Architecture
Technical Challenges and Practical Limits of Deep Learning
Despite having massive computational power, Deep Learning technology still has blind spots that any engineering team needs to anticipate before moving to production.
Hardware and Data Bottlenecks
Computing cost is a major physical barrier. Modern models consume thousands of NVIDIA GPUs running day and night. At the same time, if a complex neural network is forced to learn on too small a dataset, Overfitting occurs. The model will rote-learn the sample data perfectly but fail entirely when processing real-world data.
Out Of Memory (OOM) Error: When the Batch Size configuration is too large compared to the GPU's actual VRAM capacity during training, the system will immediately crash with a CUDA Out Of Memory error. Engineers must reduce the batch size or configure Gradient Accumulation algorithms to avoid server hangs.
The Black Box Problem
The most controversial limitation is model interpretability. Although we write the source code for the objective function, when the neural network self-adjusts billions of internal hidden weights, no engineer in the world can explain exactly why the model produced that result.
This leads to an important recommendation: Absolutely do not fully entrust life-and-death medical decisions or financial transactions to the model if business regulations require the system to be clearly interpretable.
How to Implement Deep Learning in Practice
To solve business problems, Data Scientists and Developers currently apply three main approaches, categorized by financial resources:
- Self-training from scratch: Requires a team of experts to manually configure tensors and loss functions using native libraries like PyTorch or TensorFlow. This option costs millions of dollars in Model Training infrastructure and requires ultra-large data volumes.
- Using pre-trained models: Download open-source weights on HuggingFace and Fine-tune them with a small amount of internal data to serve specific business niches.
- API Integration (Recommended for Businesses): For complex text/code tasks, the safest and most cost-optimized path is to directly call RESTful APIs of LLMs from OpenAI, Anthropic, or DeepSeek (leading LLM providers) instead of "burning money" on building systems from zero.
Frequently Asked Questions about Deep Learning
What is Deep Learning?
Deep Learning is a subset of Machine Learning that uses artificial neural networks with many processing layers to automatically extract features from unstructured data, helping computers perform complex tasks like image recognition or natural language processing.
How is Machine Learning different from Deep Learning?
Machine Learning requires humans to manually perform the feature extraction step (Feature Engineering), while Deep Learning is capable of automatically learning those features (Feature Extraction). You should choose Machine Learning for structured data and Deep Learning for large volumes of unstructured data.
Why does Deep Learning need so much computing power?
Due to the nature of Deep Learning being billions of parallel matrix multiplications in hidden layers. Training models requires powerful GPU or NPU lines to process massive data volumes and shorten the convergence time of the loss function.
What is a Transformer in Deep Learning?
A Transformer is a modern neural network architecture that uses the "Self-Attention" mechanism to process all input data in parallel. This is the core foundation of Generative AI models like ChatGPT, far superior to old sequential architectures like RNN.
What is the "Black Box" problem in Deep Learning?
This is the phenomenon where engineers cannot explain in detail how a model makes a specific decision based on internal parameters. Due to this lack of transparency, many healthcare or financial systems are cautious when applying Deep Learning.
Read more:
- Prompt Caching: How to Effectively Optimize LLM API Latency and Costs
- What Is Low-Code? A Look at Its Technical Architecture and Hidden Risks
- What Is Generative AI? Real-World Applications of Generative AI
In summary, Deep Learning is not a mystical magic trick; its essence is massive mathematical matrices performing the extraction and transformation of raw data into knowledge. This peerless power for analyzing unstructured data is leading the market but imposes a heavy burden on hardware infrastructure, GPU maintenance costs, and comes with information security risks. That is why most modern enterprises are shifting from training massive models themselves to using the APIs of leading LLMs.