Detailed Guide to Effectively Deploying AI Agents in Production

Deploying an AI Agent is the process of moving an AI agent from a development environment to production infrastructure with clear requirements for architecture, security, and scalability. This article focuses on the technical steps and practices to deploy AI Agents stably, including architectural design, infrastructure selection, state models, deployment workflows, cost optimization, testing, and quality monitoring.
Key Takeaways
- System Architecture: Understand multi-layered design to help you manage operational risks and flexibly change language models without affecting business flows.
- Deployment Infrastructure: Distinguishing between Serverless and Containers helps readers choose the appropriate environment to optimize response performance and resource costs based on the specific characteristics of each AI task type.
- State Models: Mastering Stateless, Stateful, and Event-Driven mechanisms helps you design optimal context and conversation history management for system scalability.
- Practical Workflow: Clearly knowing 5 steps from Docker packaging to Health Check setup helps standardize the process of bringing AI Agents to production in a safe, consistent, and professional manner.
- Operational Optimization: Capturing Caching and Infrastructure as Code strategies helps reduce LLM token costs and automate infrastructure management sustainably.
- Checklist Categories: Reviewing standards for security, monitoring, and resilience helps ensure AI Agents meet all technical conditions before officially serving users.
- Quality Assessment: Implementing multi-tier testing and A/B testing helps strictly control reasoning logic and continuously improve the output efficiency of AI agents.
- FAQ: Clarifying issues regarding stateless architecture, how to observe reasoning flows, and preventing API abuse to protect system resources effectively.
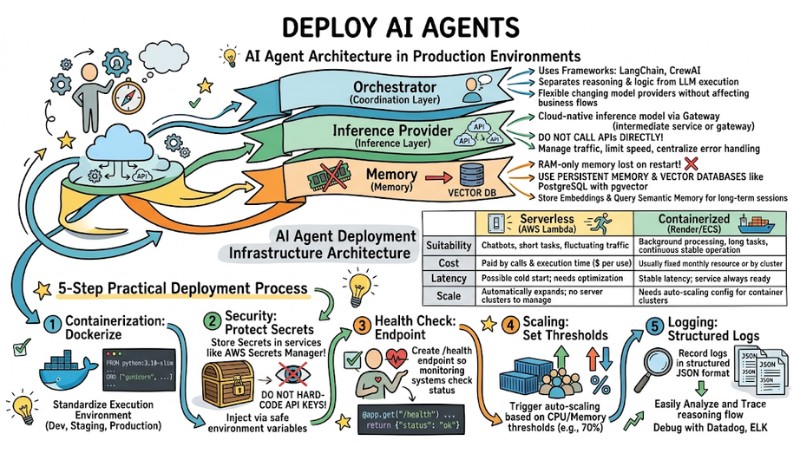
AI Agent Architecture in Production Environments
When bringing an AI Agent into a production environment, the system needs to be designed with a multi-layered architecture to support maintenance, expansion, and operational risk control.
- Orchestrator (Coordination Layer): Use frameworks like LangChain or CrewAI to separate the Agent's navigation and reasoning logic from the LLM model execution layer, allowing for flexibility in changing model providers without affecting core business flows.
- Inference Provider (Inference Layer): Apply a Cloud‑native inference model through an intermediate service or gateway instead of calling APIs directly, in order to manage traffic, limit speed, and centralize error handling.
- Memory (Memory): Limit storing the entire conversation history in RAM as data will be lost when the service restarts; instead, use persistent memory with vector databases like PostgreSQL combined with pgvector to store embeddings and query semantic memory for long-term sessions.
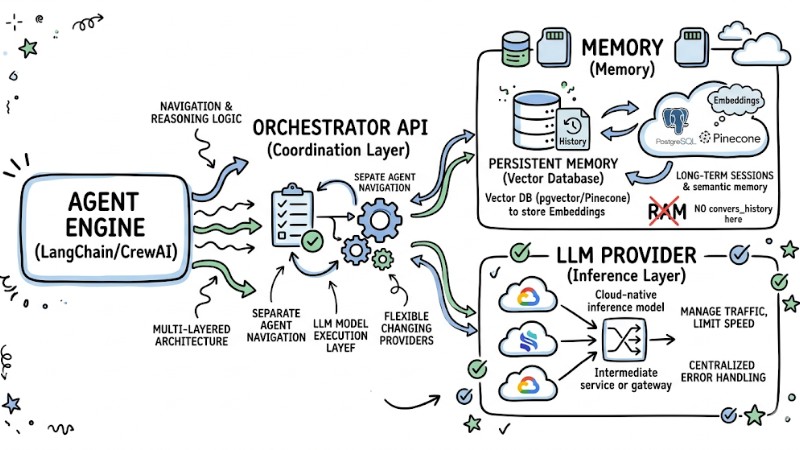
AI Agent Architecture in a Production Environment
AI Agent Deployment Infrastructure Architecture
Choosing between serverless and containers depends on the specific workload characteristics and operational requirements of the AI Agent.
| Criteria | Serverless (AWS Lambda) | Containerized (Render/ECS) |
|---|---|---|
| Suitability | Chatbots or short tasks, traffic fluctuating by time. | Background processing, long tasks, or services needing continuous stable operation. |
| Cost | Paid by number of calls and execution time. | Usually tied to fixed monthly resource costs or by container cluster. |
| Latency | Possible cold start when no instance is running; needs optimization if fast response is required. | More stable latency as the service is always ready if sufficient resources are configured. |
| Scale | Automatically expands according to request traffic without managing server clusters. | Needs auto‑scaling configuration for container clusters to meet high load periods. |
Advice: You should prioritize serverless for applications with unstable traffic or event-driven launches, and use containers for long, high-volume tasks or those requiring stable response times.
State Models of AI Agents in Production Environments
State models determine how an AI Agent manages context and stores information during processing. Choosing the right model affects system architecture, scalability, and operational complexity.
Stateless Request-Response Agent
In a stateless model, each request is processed independently and does not rely on any previously stored state. All necessary context must be sent along in the payload of each request.
This model is suitable for short, one-time tasks such as classification, data extraction, or document analysis. The system is easily scaled horizontally because there is no need to synchronize state between instances, but token costs may increase due to repeated transmission of the same context.
Stateful Session-Based Agent
In a stateful model, the agent maintains session state across multiple interactions, including conversation history and user information. State can be stored in temporary memory, Redis, or a database depending on the required retention time.
The architecture needs to clearly define where state is stored, retention duration, cleanup strategies, and how to handle instances failing while a session is active. If the state is tied to each instance, the load balancer needs to configure session affinity. If using a shared state store, every instance must be able to access it securely.
Event-Driven Asynchronous Agent
In an event-driven asynchronous model, the Agent processes tasks based on events instead of just receiving synchronous requests from the client. Users send complex tasks, receive quick confirmation, and receive results after the system completes processing via a notification mechanism or query API.
Tasks are put into a queue, workers take them out for processing, save results, and update the state accordingly. This model is suitable for long, multi-step workflows that do not require an immediate response, but requires an architecture with additional queues, worker pools, result storage, and retry mechanisms.
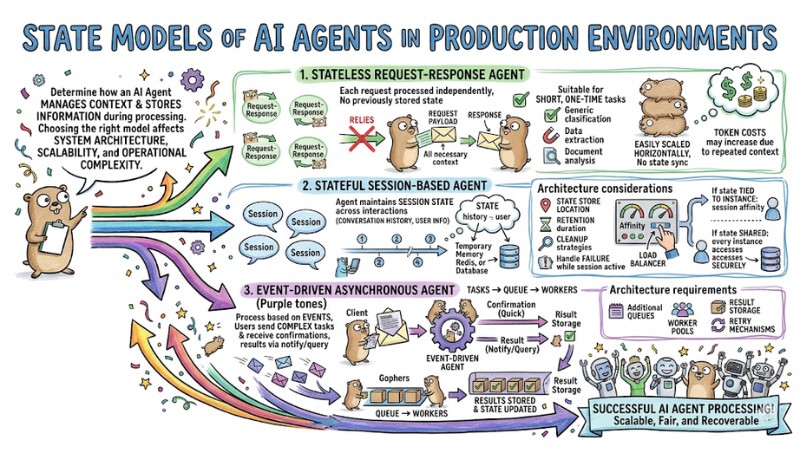
State models of AI Agents in a Production environment
5-Step Practical Deployment Process
Below are the five basic steps to package, secure, and operate an AI Agent stably in a real-world environment:
- Containerization: Package the Agent into Docker to standardize the execution environment between development, staging, and production.
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["gunicorn", "-w", "4", "-k", "uvicorn.workers.UvicornWorker", "main:app"]
- Security: Do not hard‑code API keys in the code; store secrets in services like AWS Secrets Manager or inject them via safely managed environment variables.
- Health Check: Create a
/healthendpoint so monitoring systems can check the Agent's operational status. - Scaling: Set CPU or memory thresholds, for example around 70%, to trigger auto‑scaling mechanisms when load increases.
@app.get("/health")
def health(): return {"status": "ok"}
- Logging: Record logs in structured JSON format so systems like Datadog or ELK can easily analyze and trace the Agent's reasoning flow when debugging is needed.
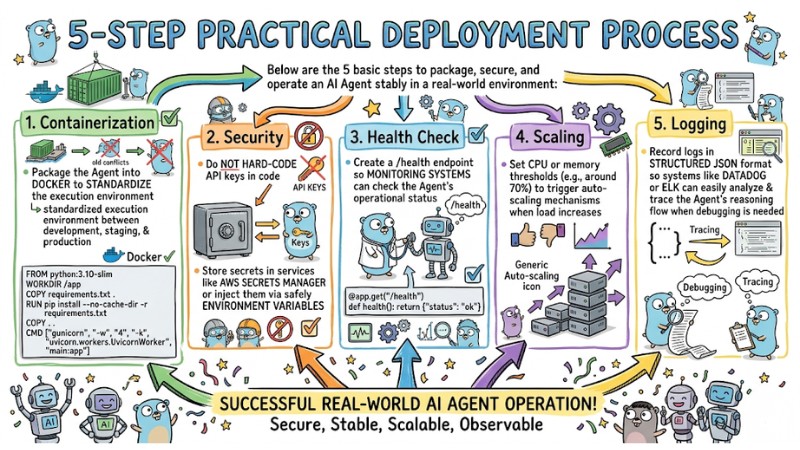
AI Agent Deployment Process
Operational Strategies and Cost Optimization for AI Agents
To operate AI Agents sustainably in a production environment, you need to simultaneously optimize token costs, infrastructure, and system performance:
- Token Optimization: Set
max_tokensat a level appropriate for each task type, apply a tiered model such as using low-cost models for classification or routing and only calling high-end models for complex reasoning requests. - Caching: Integrate Redis or equivalent cache to store results of repeated or similar prompts, thereby significantly reducing the number of LLM API calls for common questions and improving latency.
- IaC (Infrastructure as Code): Use Terraform to describe and automate infrastructure with code, helping the creation, modification, and reproduction of production environments take place consistently, quickly, and with fewer errors.
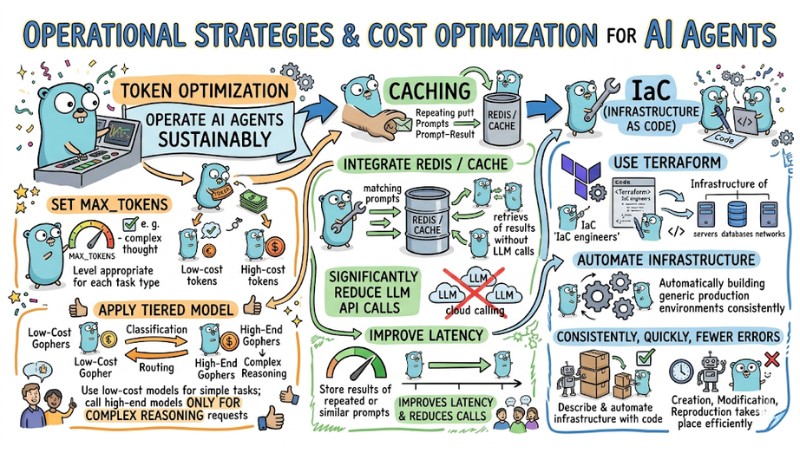
Operational and cost optimization strategies for AI Agents
Checklist Before Going to Production
Before bringing an AI Agent into a production environment, you can use the following checklist to ensure the system has met all necessary requirements:
| Category | Status |
|---|---|
| Security | API keys are protected via Secret Manager or an equivalent secret management mechanism. |
| Monitoring | System has configured logging in structured JSON format for analysis and tracing. |
| Resilience | Health check and automatic service restart mechanisms have been established for errors or lost connections. |
| Cost | Token limits have been configured and caching mechanisms implemented to control LLM calling costs. |
| Expansion | Auto‑scaling based on CPU usage thresholds or equivalent resources has been enabled to meet increased load. |
Testing and Quality Assessment of AI Agents
Testing and quality assessment help AI Agents operate stably, reduce errors, and maintain efficiency in production environments. Besides health checks and scaling, the system needs logic testing layers and continuous evaluation mechanisms to control output quality.
Unit and Integration tests for Agent workflows
Unit tests check each small component in the Agent workflow such as data processing functions, tool selection logic, or output standardization layers. The goal is to ensure each logic block works correctly for normal and edge cases, independent of the LLM.
Integration tests check the entire flow from incoming request to response, including calling the LLM (can use mocks), accessing memory stores, calling tools, and error handling. These tests help detect errors due to incorrect integration, missing configurations, or infrastructure changes causing unintended behavior.
Offline evals with test scenario sets
Offline evals use pre-prepared scenario sets, each scenario consisting of an input prompt and evaluation criteria or expected results. The system runs the Agent on this test set, measuring metrics such as task completion rate, accuracy, or scores assigned by human labelers.
These evaluations are typically performed before deploying a new version to production or when changing models, prompts, or workflows. Results help compare different configurations and select the variant with the best quality before allowing it to serve real traffic.
Online evals and A/B tests in production
Online evals use real production traffic to measure Agent quality based on user behavior and real results. The system can deploy two Agent versions (or models/prompts) in parallel and divide a portion of traffic to each version according to a pre-set ratio.
Collected metrics include the rate of tasks accepted by users, the rate of manual corrections required, completion time, and the number of tool call steps. Based on A/B test results, the operations team can choose the better-performing version and discard the less effective configuration, while continuing to iterate the quality improvement cycle.
FAQ
Is Stateless or Stateful better for AI Agents?
In production environments, stateless architecture should be prioritized, saving the entire session state and conversation history to Redis, Postgres, or external memory for easy horizontal scaling across multiple instances without depending on a specific machine.
How to observe the Agent's reasoning process?
You can use specialized observation platforms like LangSmith or Pydantic Logfire to enable tracing, tracking each LLM call, tool call, and reasoning step in an Agent session. This helps review the request path and understand why the Agent chose a specific action.
How to prevent API abuse?
Rate limiting should be configured at the API Gateway or reverse proxy layer, limiting the number of requests by user, IP, or API key within each time period. Let all requests pass through this gateway layer instead of allowing users to call directly into the Agent runtime.
Read more:
- Optimizing Coding Agent Codebases: 7 Best Practices for Developers
- Detailed Guide to Deploying a Multi-Agent System in OpenClaw
- Operating an AI Agent Teams: Risk Management for the Digital Workforce
Deploying AI Agents effectively requires combining the right multi-layer architecture, choosing suitable infrastructure, clear state modeling, and applying standardized deployment steps along with cost optimization strategies. Upon completing the production checklist and adding observation and continuous testing layers, you can operate AI Agents in real-world environments with high reliability and scalability appropriate for system needs.
Tags