AI Bias là gì? Hiểu về thiên kiến trong AI và cách kiểm soát

AI bias là hiện tượng mô hình trí tuệ nhân tạo đưa ra kết quả thiên lệch, thiếu công bằng cho một nhóm người dùng nhất định do học từ dữ liệu chứa sẵn định kiến của con người. Khi các doanh nghiệp mở rộng ứng dụng LLM vào vận hành thực tế, việc nhận diện và kiểm soát AI bias không còn là câu chuyện học thuật mà trở thành điều kiện bắt buộc để bảo vệ uy tín thương hiệu và tuân thủ các chuẩn mực đạo đức. Trong bài viết này, mình sẽ phân tích gốc rễ kỹ thuật của AI bias và các lớp phòng vệ giúp kỹ sư hệ thống giảm thiểu rủi ro trong môi trường sản xuất.
Những điểm chính
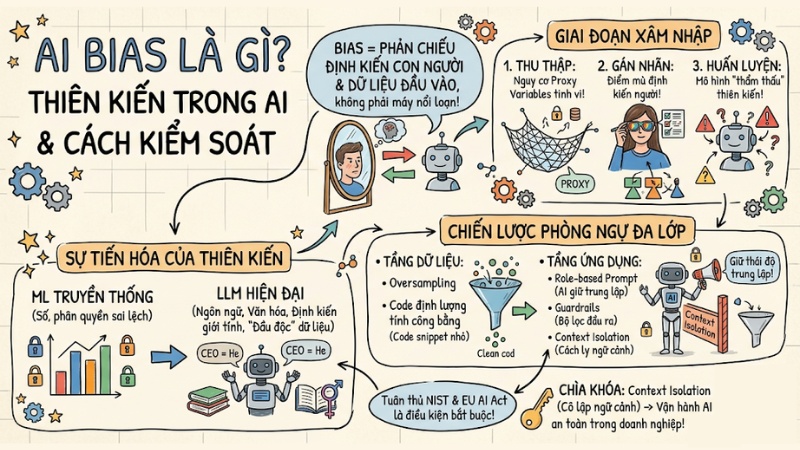
- Bản chất của AI Bias: Hiểu rõ AI Bias không phải là sự "nổi loạn" của máy móc, mà là sự phản chiếu những định kiến ẩn giấu từ con người và dữ liệu đầu vào, dẫn đến các quyết định sai lệch có hệ thống.
- Giai đoạn xâm nhập: Nắm vững 3 điểm mù (thu thập, gán nhãn, huấn luyện) nơi thiên kiến có thể len lỏi vào hệ thống, đặc biệt là nguy cơ từ các Proxy variables (biến thay thế) gây ra sự phân biệt đối xử tinh vi.
- Sự tiến hóa của thiên kiến: Phân biệt rõ rủi ro giữa Machine Learning truyền thống (sai lệch về con số/phân quyền) và LLM hiện đại (sai lệch về ngôn ngữ, văn hóa, định kiến giới tính và nguy cơ "đầu độc" dữ liệu).
- Chiến lược phòng ngự đa lớp:
- Tầng dữ liệu: Sử dụng kỹ thuật Oversampling và các thư viện đo lường để định lượng tính công bằng của mô hình bằng code thực tế.
- Tầng ứng dụng: Áp dụng Role-based prompt để ép AI giữ thái độ trung lập, thiết lập bộ lọc đầu ra (Guardrails) và thực hiện Context Isolation (cách ly ngữ cảnh) để tránh lây nhiễm chéo định kiến giữa các nhóm người dùng.
- Tuân thủ chuẩn mực: Nhận thức rằng việc kiểm soát AI Bias không còn là tùy chọn mà đã trở thành điều kiện tiên quyết để đáp ứng các khung quản trị rủi ro quốc tế như NIST và EU AI Act.
- Giải đáp FAQ: Làm rõ cách phát hiện thiên kiến, lý do tại sao LLM mặc định liên kết "CEO" với "he", và tại sao cô lập ngữ cảnh lại là "chìa khóa" để vận hành AI an toàn trong môi trường doanh nghiệp đa người dùng.
Bản chất của AI Bias
AI Bias (Thiên kiến trí tuệ nhân tạo) là sự sai lệch có hệ thống trong kết quả đầu ra của các thuật toán học máy. Điều này xảy ra khi mô hình đưa ra những quyết định thiếu công bằng hoặc phân biệt đối xử đối với một nhóm nhân khẩu học cụ thể do lỗi từ dữ liệu huấn luyện hoặc thiết kế hệ thống.
Hậu quả của thiên kiến thuật toán thường thể hiện qua việc hệ thống ưu ái một nhóm đối tượng định sẵn và gây bất lợi cho nhóm khác. Trong khoa học máy tính, hiện tượng này là minh chứng rõ nét nhất cho nguyên lý "Garbage in, Garbage out" (Đầu vào rác thì đầu ra cũng là rác). Bất kể kiến trúc mạng nơ-ron (Neural Network) của bạn phức tạp đến đâu, nếu dữ liệu đầu vào chứa đầy định kiến, kết quả dự đoán (prediction) chắc chắn sẽ bị bóp méo, tạo ra algorithmic bias.
AI Bias xâm nhập vào hệ thống từ đâu?
Thiên kiến AI không tự nhiên sinh ra, nó len lỏi vào luồng xử lý dữ liệu của hệ thống thông qua 3 giai đoạn cốt lõi sau:
- Thu thập dữ liệu.
- Tiền xử lý và gắn nhãn.
- Thiết kế và huấn luyện mô hình.
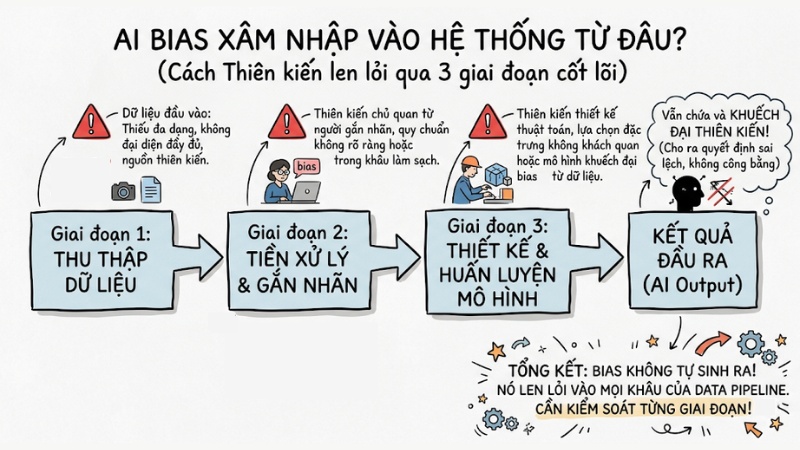
3 con đường xâm nhập của AI Bias
1. Giai đoạn thu thập
Lỗi nghiêm trọng nhất ở bước này là sử dụng dữ liệu huấn luyện bị lệch mẫu, dẫn đến hiện tượng dữ liệu không đại diện.
Ví dụ:*** Nếu bạn huấn luyện một mô hình gợi ý sản phẩm cho sàn thương mại điện tử nhưng 80% dữ liệu lịch sử chỉ đến từ ngành thời trang, mô hình sẽ có xu hướng ưu tiên đề xuất quần áo và giày dép, và hoạt động kém hiệu quả khi phải gợi ý sản phẩm ở các ngành khác như điện tử hoặc đồ gia dụng. Mô hình AI không có ý thức, nó chỉ học từ chính xác những gì nó được ‘nhìn’ thấy trong dữ liệu huấn luyện.*
2. Giai đoạn tiền xử lý và gắn nhãn
Đây là giai đoạn yếu tố con người tác động trực tiếp vào bộ não của hệ thống thông qua quy trình gắn nhãn dữ liệu. Những chuyên viên gán nhãn suy cho cùng vẫn là con người. Khi phải ngồi phân tích và gán nhãn cho hàng nghìn file JSON hoặc CSV mỗi ngày, sự mệt mỏi và định kiến vô thức của họ sẽ bị "hard-code" vĩnh viễn vào hệ thống.
Nếu một chuyên viên gắn nhãn có thiên kiến và liên tục gán nhãn "tiêu cực" cho các câu văn mang phương ngữ của một vùng miền cụ thể, mô hình sẽ mặc định vùng miền đó đồng nghĩa với sự độc hại.
2.3. Giai đoạn thiết kế và huấn luyện
Ngay cả khi kỹ sư có trong tay một tập dữ liệu sạch hoàn hảo, data bias vẫn có thể phát sinh do kiến trúc trích xuất đặc trưng của thuật toán. Rủi ro khó nắm bắt nhất ở giai đoạn này là hiện tượng Proxy variables (Biến thay thế).
Ví dụ: Với một mô hình chấm điểm tín dụng ngân hàng: Để đảm bảo tính công bằng, Dev đã chủ động xóa cột "Chủng tộc" khỏi tập dữ liệu. Tuy nhiên, thuật toán học sâu (Deep Learning) lại tự động tìm ra mối tương quan ẩn giữa cột "Mã bưu chính" (ZIP code) và tỷ lệ vỡ nợ. Vì các khu vực địa lý thường có sự phân hóa dân cư theo sắc tộc, mô hình đã dùng mã bưu chính làm biến thay thế (proxy) để ngầm suy luận ra chủng tộc, từ đó tiếp tục từ chối khoản vay của các nhóm thiểu số một cách cực kỳ tinh vi.
Từ Machine Learning đến LLM: AI Bias tiến hóa ra sao?
Sự dịch chuyển từ các mô hình học máy (machine learning) dự đoán số liệu sang các mô hình ngôn ngữ lớn (LLMs) sinh văn bản đã làm thay đổi hoàn toàn hình thái của thiên kiến.
| Tiêu chí | Machine Learning truyền thống | Generative AI / LLMs |
|---|---|---|
| Dữ liệu đầu vào | Dữ liệu có cấu trúc (Bảng biểu, CSV, Database). | Dữ liệu phi cấu trúc (Văn bản internet, sách, mã nguồn). |
| Dạng Output | Xác suất số học, phân loại nhãn. | Văn bản tự do, mã code, hình ảnh. |
| Tính minh bạch | Dễ dàng trace (truy vết) lại trọng số. | Hộp đen (Black-box), khó giải thích cơ chế sinh từ. |
| Đặc điểm Bias | Thiên lệch về phân quyền, dự đoán điểm số. | Khuôn mẫu ngôn ngữ, ảo giác văn hóa, định kiến giới tính. |
1. Các "thảm họa" Machine Learning trong quá khứ
Trước kỷ nguyên của Generative AI, thiên kiến thuật toán chủ yếu gây ra hậu quả về việc phân bổ nguồn lực dựa trên các con số.
- Sàng lọc CV của Amazon: Thuật toán tuyển dụng tự động đánh tụt điểm hồ sơ của ứng viên nữ. Nguyên nhân là do hệ thống được train trên tệp CV lịch sử 10 năm của Amazon, nơi phần lớn nhân sự kỹ sư trúng tuyển là nam giới.
- Hệ thống Y tế Mỹ: Một thuật toán dự đoán rủi ro đã ưu tiên chăm sóc bệnh nhân da trắng hơn bệnh nhân da màu. Sai lầm nằm ở chỗ hệ thống dùng "chi phí y tế lịch sử" làm proxy dự đoán bệnh tật, bỏ qua sự thật rằng các nhóm thiểu số thường có ít điều kiện tài chính để chi trả y tế trong quá khứ hơn.
2. Thiên kiến trong Generative AI và LLM hiện đại
Với các LLMs, thiên lệch xuất hiện tinh vi qua Token/Language bias. Vì LLM hoạt động dựa trên xác suất dự báo token tiếp theo từ kho ngữ liệu khổng lồ chứa đầy khuôn mẫu trên Internet, nó mặc định liên kết từ khóa "CEO" với đại từ "he" thay vì "she".
Đặc biệt, sự chênh lệch dữ liệu tạo ra rào cản lớn với các ngôn ngữ ít tài nguyên như tiếng Việt. Việc prompt bằng tiếng Việt thường đem lại output ngớ ngẩn hoặc thiếu an toàn hơn rất nhiều so với tiếng Anh. Ngoài ra, LLM còn đối mặt với rủi ro Data Poisoning (Đầu độc dữ liệu) – khi hacker cố tình tiêm nhiễm dữ liệu độc hại trong quá trình tinh chỉnh (Fine-tuning) để phá vỡ tính minh bạch của model.
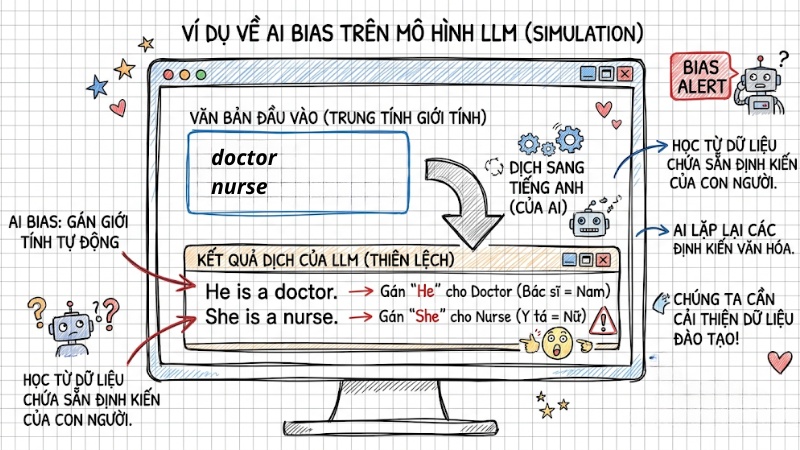
AI tự động gán từ "doctor" cho "he" và "nurse" cho "she"
Kỹ sư cần làm gì để giảm thiểu AI Bias?
Bạn không thể mong chờ một mô hình Foundation Model hoàn toàn "zero-bias". Để kiểm soát rủi ro, hệ thống cần được thiết kế dựa trên kiến trúc phòng ngự đa lớp.
1. Can thiệp ở tầng dữ liệu và đánh giá
Trước khi đưa hệ thống lên môi trường production, việc đánh giá mô hình bằng toán học là yêu cầu bắt buộc. Ở tầng dữ liệu, các kỹ sư thường dùng kỹ thuật Oversampling (tăng cường dữ liệu cho nhóm thiểu số) để tái cân bằng dataset.
Để đo lường bằng code thực tế, bạn có thể sử dụng thư viện Fairlearn hoặc AI Fairness 360 trong Python. Dưới đây là mẫu đo lường sự chênh lệch nhân khẩu học:
from fairlearn.metrics import demographic_parity_difference
from sklearn.metrics import accuracy_score
# y_true: Kết quả thực tế, y_pred: Kết quả dự đoán của AI
# sensitive_features: Cột dữ liệu chứa biến nhạy cảm (Ví dụ: Giới tính, Chủng tộc)
# Tính toán sự chênh lệch tỷ lệ dự đoán tích cực giữa các nhóm
dp_diff = demographic_parity_difference(
y_true=y_true,
y_pred=y_pred,
sensitive_features=sensitive_features
)
print(f"Chênh lệch công bằng nhân khẩu học: {dp_diff:.4f}")
# Lưu ý: Nếu giá trị này lớn hơn mức cơ sở (ví dụ: > 0.1),
# mô hình đang có dấu hiệu thiên kiến rõ rệt đối với một nhóm nhạy cảm.
Những bài test này không chỉ giải quyết bài toán đạo đức AI, mà còn là nền tảng để hệ thống của bạn tuân thủ khung quản trị rủi ro AI từ NIST (Mỹ) và chuẩn bị cho các quy định khắt khe từ EU AI Act.
2. Can thiệp ở tầng ứng dụng và điều phối (Application Layer)
Mindset quan trọng nhất của một kỹ sư là: "Base model luôn có bias, bắt buộc phải chặn đứng nó ở tầng App". Bạn có thể áp dụng các rào cản kỹ thuật sau:
- Role-based prompt: Đóng gói prompt của người dùng vào một System Prompt ẩn, ép LLM phải phân tích vấn đề đa chiều và giữ thái độ trung lập.
- Policy Control: Cấu hình các bộ lọc cứng đầu ra (Guardrails) chặn các từ khóa mang tính chất rập khuôn.
- Context Isolation (Cách ly ngữ cảnh): Trong kiến trúc Multi-tenant (nhiều người dùng), nếu không cô lập bộ nhớ của LLM, dữ liệu của User A sẽ ngầm định hướng sang User B, gây lây nhiễm chéo định kiến. Việc mã hóa và cấp phát không gian Context riêng biệt cho từng người dùng là cốt lõi của việc quản trị AI an toàn.
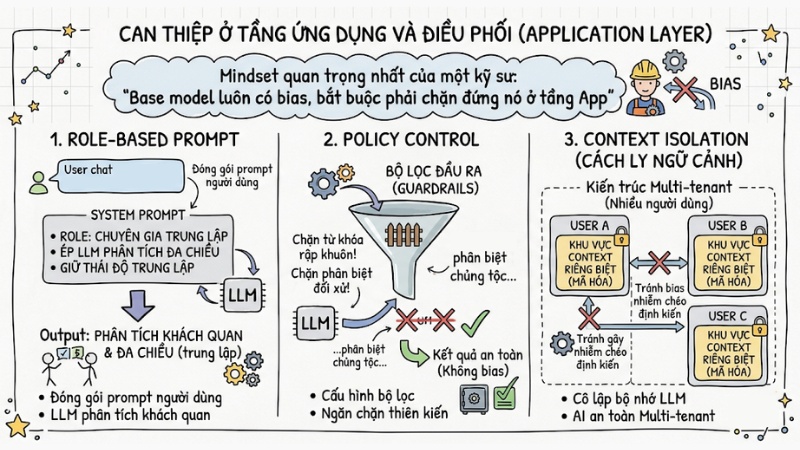
Can thiệp ở tầng ứng dụng và điều phối
Câu hỏi thường gặp về AI Bias
AI bias (thiên kiến trí tuệ nhân tạo) là gì?
AI bias là sự sai lệch có hệ thống trong kết quả của mô hình AI, phát sinh khi thuật toán phản ánh định kiến của con người hoặc dữ liệu huấn luyện không đại diện. Hiện tượng này dẫn đến các quyết định bất công, phân biệt đối xử dựa trên giới tính, chủng tộc hoặc các đặc điểm nhạy cảm khác.
Nguyên nhân chính gây ra thiên kiến trong các mô hình AI?
Thiên kiến xâm nhập qua ba giai đoạn:
- Dữ liệu huấn luyện không đại diện (tập dữ liệu thiếu đa dạng).
- Sự chủ quan của con người khi gắn nhãn.
- Việc sử dụng các "biến thay thế".
Làm thế nào để phát hiện và đo lường AI bias trong hệ thống?
Các kỹ sư thường sử dụng các thư viện chuyên dụng như Fairlearn hoặc AI Fairness 360 để đánh giá độ công bằng của mô hình trên các nhóm nhân khẩu học khác nhau. Việc giám sát định kỳ thông qua kiểm thử "thử thách" là bước bắt buộc trong quản trị rủi ro AI.
Tại sao LLM lại dễ bị ảnh hưởng bởi thiên kiến ngôn ngữ?
LLM học xác suất từ các kho dữ liệu (corpus) khổng lồ do con người tạo ra, nơi vốn dĩ tồn tại các rập khuôn về từ vựng (ví dụ: mặc định kết hợp "bác sĩ" với nam giới). Điều này khiến mô hình tự động tái tạo và khuếch đại các định kiến giới tính hoặc văn hóa sẵn có.
Giải pháp kỹ thuật nào giúp giảm thiểu rủi ro AI bias cho doanh nghiệp?
Doanh nghiệp nên áp dụng chiến lược đa lớp: Tiền xử lý dữ liệu để cân bằng tập mẫu, sử dụng kỹ thuật Role-based prompt để ép mô hình trung lập, và triển khai kiến trúc Context Isolation (cách ly ngữ cảnh) để đảm bảo dữ liệu người dùng không bị nhiễm chéo, giúp hệ thống vận hành an toàn và minh bạch.
Xem thêm:
- Natural Language Processing (NLP) là gì? Vai trò và ứng dụng thực tế
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
- Prompt Caching: Cách tối ưu độ trễ và chi phí API LLM hiệu quả
Nhìn nhận một cách tổng quan, ai bias không phải là lỗi sinh ra từ sự "nổi loạn" của cỗ máy, mà chính là tấm gương chân thực nhất phản chiếu các định kiến ẩn giấu trong dữ liệu của con người. Việc quản trị rủi ro AI không thể giải quyết triệt để chỉ bằng cách làm sạch file CSV, mà đòi hỏi một tư duy thiết kế kiến trúc hệ thống đa lớp từ đánh giá thuật toán cho đến quản lý ngữ cảnh ứng dụng.