MLOps là gì? Cách xây dựng Machine Learning Pipeline chuẩn

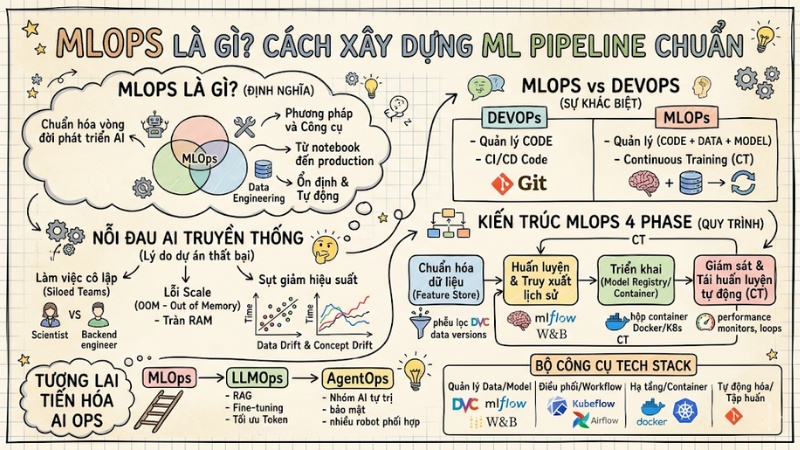
MLOps (Machine Learning Operations) là tập hợp phương pháp và công cụ giúp đưa mô hình máy học từ môi trường local vào môi trường production một cách ổn định, tự động và có thể giám sát được. Phương pháp này chuẩn hóa toàn bộ Machine Learning Pipeline (từ dữ liệu, huấn luyện, triển khai đến giám sát và tái huấn luyện) để mô hình tạo ra giá trị bền vững cho doanh nghiệp, thay vì chỉ tập trung vào độ chính xác trên môi trường cục bộ. Trong bài viết này, chúng mình sẽ phân tích nguyên nhân khiến dự án AI thất bại, cách chuẩn hóa luồng dữ liệu để bạn hiểu rõ MLOps là gì.
Những điểm chính
- Bản chất MLOps: Hiểu MLOps là sự giao thoa chiến lược giữa Machine Learning, Data Engineering và DevOps nhằm chuẩn hóa vòng đời phát triển AI, giúp chuyển dịch từ việc "chạy model trên Notebook" sang "vận hành AI bền vững trên Production".
- Giải mã nỗi đau vận hành: Nắm vững lý do các dự án AI thất bại do làm việc cô lập (Siloed Teams), lỗi OOM (Out of Memory) khi scale, và sự suy giảm hiệu suất mô hình do hiện tượng Data Drift & Concept Drift theo thời gian.
- Phân biệt DevOps với MLOps: Nhận diện sự khác biệt sống còn: DevOps quản lý Code, trong khi MLOps phải quản lý bộ ba phức tạp gồm Code, Data và Model, cùng với vòng lặp Continuous Training (CT) tự động.
- Kiến trúc MLOps 4 Phase: Thiết lập pipeline chuyên nghiệp gồm: Chuẩn hóa dữ liệu -> Huấn luyện và truy xuất lịch sử -> Triển khai -> Giám sát và tái huấn luyện tự động.
- Bộ công cụ Tech Stack: Làm chủ hệ sinh thái công cụ hiện đại: DVC (quản lý phiên bản dữ liệu lớn), Kubeflow/Airflow (điều phối quy trình), và Docker/K8s (tối ưu hạ tầng GPU).
- Tiến hóa lên LLMOps và AgentOps: Hiểu xu hướng dịch chuyển từ việc quản lý Tensor/Weights sang LLMOps (Fine-tuning, RAG, tối ưu Token) và AgentOps (điều phối nhóm AI tự trị, bảo mật trong môi trường Multi-tenant).
- Giải đáp FAQ: Làm rõ vai trò của MLOps trong việc xóa bỏ khoảng cách giữa Data Scientist và Backend, cách xử lý Data Drift bằng Continuous Training, và tại sao MLOps là "cầu nối" đưa AI từ thử nghiệm thành lợi nhuận thực tế.
Định nghĩa MLOps và nỗi đau của Machine Learning truyền thống
MLOps (Machine Learning Operations) là tập hợp các phương pháp luận, văn hóa và quy trình kỹ thuật nhằm chuẩn hóa và tự động hóa toàn bộ vòng đời phát triển hệ thống machine learning (ML Lifecycle). Đây là sự giao thoa cốt lõi giữa Machine Learning, DevOps và Data Engineering trong môi trường production.
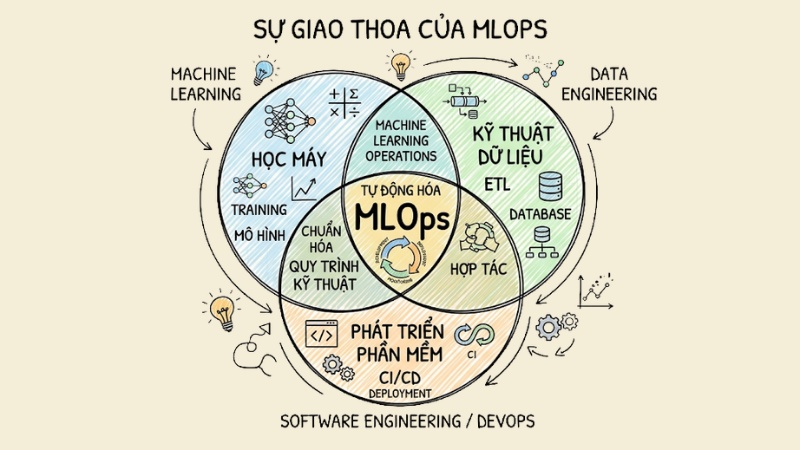
MLOps là sự giao thoa cốt lõi giữa Machine Learning, DevOps và Data Engineering
Tại sao các doanh nghiệp công nghệ lại khao khát ứng dụng MLOps? Hãy nhìn vào những "nỗi đau" của phương pháp triển khai AI truyền thống:
- Siloed Teams (Làm việc cô lập): Team Data viết code Python, train model rồi chuyển cho team Software Engineer dưới dạng một file trọng số (weights). Team Dev chỉ bọc file đó trong một API (như FastAPI) mà không hiểu rõ cơ chế Tensor hay kiến trúc tính toán phía sau, khiến khoảng cách hiểu biết giữa hai bên dễ sinh ra nhiều lỗi khó truy vết.
- Lỗi OOM (Out of Memory): Khi triển khai lên server, kỹ sư phần mềm có thể cấu hình sai batch size hoặc bỏ qua giới hạn bộ nhớ. Điều này dẫn đến việc mô hình tiêu thụ RAM vượt ngưỡng, gây tràn bộ nhớ và làm sập toàn bộ cluster khi lưu lượng request tăng đột biến.
Hiệu ứng trôi dữ kiệu: Khi mô hình AI xuống cấp theo thời gian
Phần mềm truyền thống sau khi được biên dịch sẽ chạy ổn định theo logic tĩnh. Ngược lại, các hệ thống AI có bản chất động. Hiệu suất của model sẽ suy giảm dần theo thời gian (Model Degradation) do hai nguyên nhân chính:
- Data Drift (Trôi dạt dữ liệu): Phân phối thống kê của dữ liệu đầu vào trong thực tế bị biến đổi so với tập dữ liệu gốc dùng để huấn luyện mô hình.
- Concept Drift (Trôi dạt khái niệm): Mối quan hệ logic giữa Input và Output thay đổi (Ví dụ: Định nghĩa "giao dịch gian lận" phải cập nhật liên tục theo thủ đoạn mới của hacker).
Hiểu rõ MLOps là gì giúp bạn xây dựng hệ thống có khả năng tự động nhận diện những thay đổi dữ liệu này để khắc phục kịp thời.
Phân biệt DevOps và MLOps
Nhiều lập trình viên lầm tưởng rằng chỉ cần thiết lập CI/CD cho dự án AI là đã hoàn thành MLOps. Đây là một sai lầm nghiêm trọng về mặt tư duy hệ thống.
Trong khi DevOps chủ yếu quản lý Code thì MLOps phải giải quyết bài toán phức tạp hơn với ba yếu tố: Code, Data và Model. Sự khác biệt cốt lõi và mang tính sống còn giữa DevOps và MLOps là khái niệm Continuous Training (CT) - phần mềm không tự sửa code, nhưng AI phải tự động nạp dữ liệu mới để cập nhật trọng số.
| Tiêu chí kỹ thuật | DevOps (Software Engineering) | MLOps (Machine Learning) |
|---|---|---|
| Đối tượng quản lý | Code phần mềm, Cấu hình hạ tầng. | Code, Dữ liệu (Data), Mô hình (Model). |
| Vòng lặp tự động hóa | CI/CD (Tích hợp & Triển khai liên tục). | CI/CD + Continuous Training (CT). |
| Mục tiêu tối ưu | Phần mềm không bug, Uptime 99.9%. | Độ chính xác (Accuracy, F1-Score, Loss). |
| Nguyên nhân gây lỗi | Lỗi logic code, sập server, sai config. | Data Drift, Concept Drift, Data Quality. |
| Tài nguyên tính toán | CPU, RAM tiêu chuẩn (Dễ scale). | Yêu cầu cao về GPU, VRAM, Compute Cost. |
| Giám sát | Latency, Memory usage, Error Rate. | Tương tự DevOps + Model Performance. |
Sự khác biệt trong Testing và Versioning:
- Về quy trình Testing: Trong DevOps, bạn viết Unit Test hoặc Integration Test để đảm bảo hàm chạy đúng logic. Tuy nhiên, MLOps yêu cầu khắt khe hơn. Bạn phải thực hiện Data Validation (kiểm tra phân phối dữ liệu, missing values), sau đó chạy Shadow Deployment (triển khai ẩn model mới song song với model cũ) để kiểm chứng tỷ lệ dự đoán chính xác trên production.
- Về Versioning: Sử dụng Git là tiêu chuẩn vàng của DevOps. Tuy nhiên, Git trở nên kém hiệu quả với các tập dữ liệu hàng trăm GB hoặc file weights cực lớn. MLOps bắt buộc phải dùng Semantic Versioning cho Data và Model. Nhờ đó, kỹ sư đảm bảo được khả năng Reproducibility (tái tạo lại chính xác kết quả train dựa trên đúng phiên bản data và code trong quá khứ).
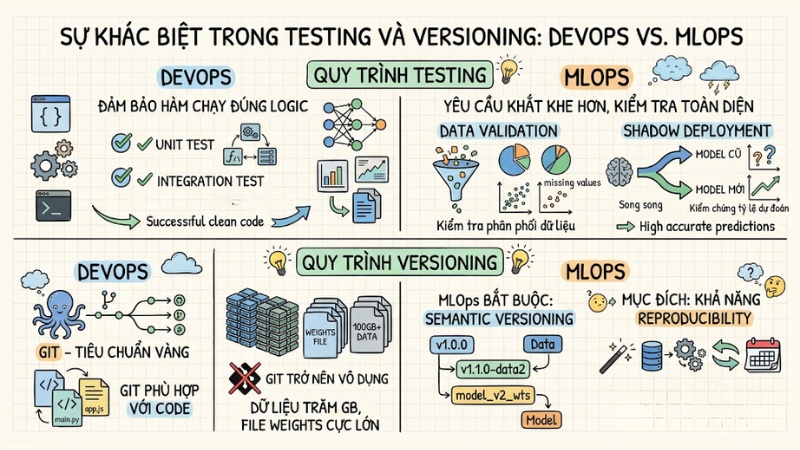
Sự khác biệt trong Testing và Versioning
Kiến trúc chuẩn của một MLOps Pipeline
Để hạn chế nguy cơ hệ thống “vỡ trận” khi scale, kỹ sư dữ liệu thường bám theo các kiến trúc tham chiếu từ AWS hoặc GCP thay vì dồn toàn bộ tiền xử lý và huấn luyện vào một file notebook duy nhất.
Một Machine Learning Pipeline chuyên nghiệp, sẵn sàng cho production, luôn được tách thành 4 giai đoạn độc lập nhưng liên kết chặt chẽ với nhau như sau:
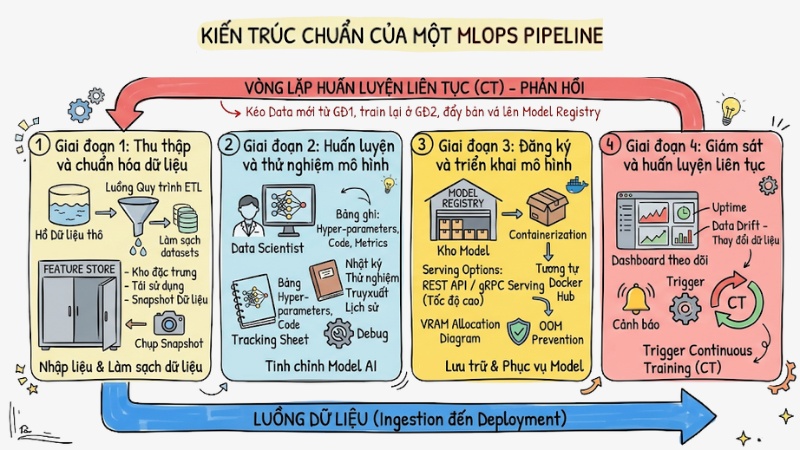
Kiến trúc chuẩn của một MLOps Pipeline
Giai đoạn 1: Thu thập và chuẩn hóa dữ liệu
Đây là bước nhập liệu và làm sạch dữ liệu. Dữ liệu thô từ Data Lake được trích xuất và biến đổi qua các luồng quy trình ETL. Điểm sáng kiến trúc ở giai đoạn này là Feature Store – kho lưu trữ các đặc trưng đã qua xử lý.
Công cụ này giúp các team nội bộ tái sử dụng dữ liệu sạch mà không phải tính toán lại từ đầu. Kỹ thuật Data Versioning cũng được kích hoạt để "chụp snapshot" tập data.
Giai đoạn 2: Huấn luyện và thử nghiệm mô hình
Môi trường thử nghiệm là nơi các Nhà khoa học Dữ liệu tinh chỉnh mô hình AI. Quá trình này bắt buộc phải tracking toàn bộ các Hyper-parameters (siêu tham số), source code, và metrics.
Mục tiêu tối thượng của Machine Learning Pipeline ở bước này là khả năng truy xuất lịch sử. Nếu bỏ qua bước này, việc debug một model gặp lỗi ảo giác trên production sẽ rơi vào bế tắc.
Giai đoạn 3: Đăng ký và triển khai mô hình
Sau khi huấn luyện, model tốt nhất không được đẩy thẳng ra ngoài mà lưu vào Model Registry (kho lưu trữ tương tự Docker Hub nhưng tối ưu cho AI). Khi sẵn sàng, quá trình triển khai mô hình (Model Deployment) sẽ diễn ra.
Mô hình được đóng gói (Containerization) cùng thư viện môi trường. Tùy theo yêu cầu Latency, Model Deployment có thể phục vụ dạng REST API hoặc gRPC Serving tốc độ cao. Đây cũng là phase hệ thống xử lý triệt để việc phân bổ VRAM, ngăn chặn triệt để lỗi OOM.
Giai đoạn 4: Giám sát và huấn luyện liên tục
Hệ thống MLOps sẽ không hiệu quả nếu thiếu vòng lặp giám sát. Giai đoạn này không chỉ theo dõi Uptime mà còn quét liên tục để tìm dấu hiệu phân phối dữ liệu thay đổi. Khi nhận diện cảnh báo, hệ thống tự động trigger vòng lặp huấn luyện liên tục. Nó kéo dữ liệu mới từ giai đoạn 1, tiến hành train lại ở giai đoạn 2, và đẩy bản vá lên Model Registry hoàn toàn tự động.
Tech Stack tiêu biểu cho MLOps Engineer
Hệ sinh thái công cụ AI thay đổi gần như từng ngày, nhưng một kỹ sư MLOps Senior không chạy theo công cụ mới mà ưu tiên đặt mỗi tool vào đúng phase trong toàn bộ pipeline. Dưới đây là các nhóm công cụ MLOps tiêu chuẩn thường được sử dụng trong một kiến trúc hệ sinh thái hoàn chỉnh.
- Quản lý phiên bản dữ liệu và mã nguồn: DVC (Data Version Control) hoặc Pachyderm là giải pháp phù hợp để lưu trữ snapshot dữ liệu siêu lớn mà Git truyền thống không đáp ứng được.
- Theo dõi thực nghiệm: MLflow hoặc Weights & Biases (W&B) thường được sử dụng ở giai đoạn 2 để lưu lại toàn bộ lịch sử tùy chỉnh siêu tham số và hàm loss.
- Điều phối: Apache Airflow, Kubeflow đóng vai trò là nhạc trưởng điều phối, quyết định tác vụ nào chạy song song hay tuần tự trong pipeline.
- Đóng gói Container và hạ tầng: Docker và Kubernetes (K8s) giúp cấp phát tài nguyên GPU linh hoạt, đảm bảo môi trường nhất quán từ môi trường cục bộ lên cloud.
- Triển khai mô hình: TensorFlow Serving, TorchServe hoặc FastAPI là các giải pháp tối ưu hóa thông lượng và giảm thiểu độ trễ cho API.
import mlflow
# Khởi tạo MLflow tracking
mlflow.set_experiment("Fraud_Detection_Pipeline")
with mlflow.start_run():
# Log các siêu tham số
mlflow.log_param("batch_size", 64)
mlflow.log_param("learning_rate", 0.001)
#Giả lập quá trình train
accuracy=train_model()
# Log kết quả metrics
mlflow.log_metric("accuracy", accuracy)
# Lưu model vào Model Registry nội bộ
mlflow.sklearn.log_model(sk_model=model, artifact_path="model_output")
Việc áp dụng triệt để các công cụ MLOps này giúp định hình lại luồng công việc, xóa bỏ vấn đề làm việc cô lập giữa Nhà khoa học Dữ liệu và Lập trình viên Backend.
Sự tiến hóa tương lai: Từ MLOps đến LLMOps và AgentOps
Công nghệ cốt lõi của AI đang thay đổi với tốc độ chóng mặt, đặc biệt sau làn sóng mô hình ngôn ngữ lớn (LLMs), khiến cách tiếp cận MLOps truyền thống buộc phải thay đổi. Nguyên nhân là vì việc tự train model từ đầu với chi phí hàng triệu đô la ngày càng kém thực tế.
Kỷ nguyên LLMOps dịch trọng tâm sang fine-tuning (LoRA, QLoRA), RAG và Prompt Engineering, nơi bài toán không chỉ là quản lý Tensor, mà còn bao gồm việc kiểm soát context window, chi phí token và giảm thiểu ảo giác.
Xa hơn nữa, AgentOps xuất hiện như lớp tiến hóa tiếp theo: thay vì một mô hình đơn lẻ, hệ thống phải vận hành cả một đội ngũ AI Agent. Điều này đặt ra những thách thức mới về ủy quyền nhiệm vụ, chia sẻ ngữ cảnh và bảo mật trong môi trường doanh nghiệp đa người dùng.
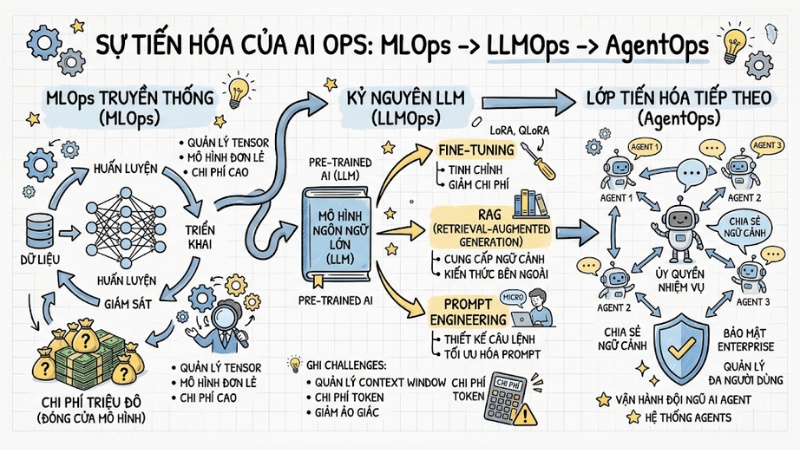
Sự tiến hóa tương lai: Từ MLOps đến LLMOps và AgentOps
Câu hỏi thường gặp về MLOps
MLOps là gì?
MLOps (Machine Learning Operations) là bộ quy trình chuẩn hóa giúp tự động hóa vòng đời máy học, từ khâu phát triển, kiểm thử đến triển khai. Nó kết hợp văn hóa DevOps, kỹ thuật dữ liệu và khoa học máy học để đảm bảo mô hình vận hành ổn định, chính xác trên môi trường thực tế.
Tại sao cần triển khai MLOps trong dự án AI?
MLOps giúp giải quyết bài toán 'vỡ mộng' khi đưa AI từ Jupyter Notebook lên môi trường production. Nó tự động hóa quy trình quản lý, giúp phát hiện sớm hiện tượng suy giảm hiệu năng (Data Drift), đảm bảo tính tái lập và giảm thiểu lỗi vận hành do sai lệch giữa môi trường huấn luyện và thực tế.
Sự khác biệt chính giữa DevOps và MLOps là gì?
Sự khác biệt chính nằm ở phạm vi và cách quản lý hệ thống theo thời gian. DevOps chủ yếu lo vòng đời code của phần mềm, còn MLOps phải quản lý thêm dữ liệu và mô hình, nên cần cơ chế Continuous Training để mô hình tự được huấn luyện lại khi dữ liệu thực tế thay đổi.
Các công cụ MLOps phổ biến nhất hiện nay gồm những gì?
Các công cụ tiêu chuẩn bao gồm:
- Quản lý phiên bản dữ liệu: DVC, LakeFS.
- Theo dõi thực nghiệm: MLflow, Weights & Biases.
- Điều phối quy trình (Orchestration): Airflow, Kubeflow.
- Containerization & Serving: Docker, Kubernetes, FastAPI, TF Serving.
Làm thế nào để giải quyết vấn đề Data Drift trong MLOps?
Bạn cần thiết lập hệ thống giám sát liên tục để theo dõi các phân phối dữ liệu đầu vào. Khi dữ liệu thực tế lệch khỏi dữ liệu huấn luyện, hệ thống sẽ tự động kích hoạt quy trình "Continuous Training" để tái huấn luyện mô hình với dữ liệu mới, đảm bảo độ chính xác.
Sự khác biệt giữa MLOps và LLMOps/AgentOps là gì?
MLOps quản lý vòng đời mô hình học máy truyền thống, LLMOps tập trung vào fine-tuning và tối ưu hóa prompt cho LLM, còn AgentOps là cấp độ cao hơn, tập trung vào quản lý, điều phối và bảo mật các AI Agent tự vận hành, thực hiện tác vụ phức tạp theo nhóm thông qua các giao thức như MCP.
Xem thêm:
- Tư duy AI-First là gì? Lợi ích và cách ứng dụng cho doanh nghiệp
- AI Bias là gì? Hiểu về thiên kiến trong AI và cách kiểm soát
- Deep Learning là gì? Phân tích kiến trúc và bản chất học sâu
Tóm lại, MLOps là bộ khung vận hành giúp mô hình máy học hoạt động hiệu quả không chỉ trên notebook mà còn trong môi trường production, đối mặt với dữ liệu thay đổi và áp lực mở rộng hệ thống. Doanh nghiệp nắm vững MLOps (từ pipeline 4 giai đoạn, testing, versioning đến monitoring, cùng các thế hệ mới như LLMOps, AgentOps) sẽ có lợi thế rõ rệt trong việc biến AI từ thử nghiệm thành giá trị kinh doanh thực tế, bền vững.