What is Fine-tuning? Benefits and Applications of AI Refinement

Fine-tuning is a technique for refining a pre-trained Large Language Model (LLM) so that the model adapts its knowledge and behavior to a specific business problem. Instead of accepting generic answers from GPT-4, Claude, or Llama 3, you can turn a foundation model into a customized version that strictly adheres to your internal tone of voice, processes, and industry specifics. In this article, I will analyze the technical nature, operating mechanisms, and provide a framework to help you decide when you should (or should not) invest in fine-tuning to avoid wasting infrastructure costs.
Key Takeaways
- Nature of Fine-tuning: Understand that this is a technique for foundation models, helping to customize AI according to an enterprise's own style, processes, and terminology instead of building a model from scratch.
- Breakthrough Technical Mechanism: Master the role of PEFT (such as LoRA) techniques in refining only <1% of model weights, helping businesses save on massive GPU computing costs while still achieving specialized effectiveness.
- Distinguishing Fine-tuning, RAG, and Prompting: Identify the right problem: use Prompting for steering, RAG for adding dynamic knowledge, and Fine-tuning for deep behavior/style shaping.
- Smart Investment Strategy: Apply the mindset of "exhausting" effectiveness from Prompt Engineering and RAG before deciding to invest in Fine-tuning to avoid wasting data and infrastructure budgets.
- Core Risks: Recognize the cost "black hole" from the Data Labeling stage and the risk of Overfitting (model rote-learning, losing general reasoning ability) when refinement data is of poor quality.
- Investment-worthy Use-cases: Pinpoint 3 practical scenarios requiring Fine-tuning: consistent Brand Voice, strict output formatting (JSON/XML), and absorbing niche context (Medical, Legal, Internal Code).
- FAQ Resolution: Clarify the difference between refinement and knowledge retrieval, how to use LoRA techniques to optimize resources, and strategies to ensure sensitive data security during the refinement process.
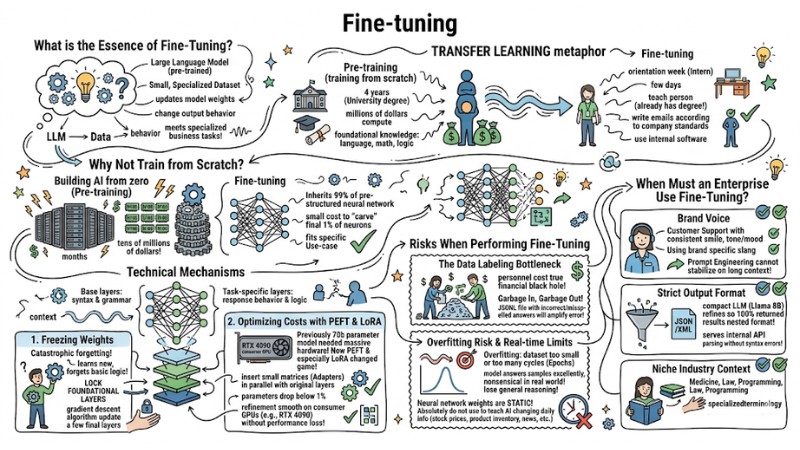
What is the Essence of Fine-Tuning?
Definition of Fine-Tuning
Fine-tuning is the process of taking a pre-trained Large Language Model and continuing its training on a small, specialized dataset. Specifically, this technique updates a portion of the model's weights to change its output behavior. This helps the AI accurately meet specialized business tasks instead of just providing general knowledge.
To visualize this, we can use a metaphor for Transfer Learning. Specifically, the Pre-training process (training from scratch) is like someone completing a University degree. They spend 4 years (and millions of dollars in compute) to gain foundational knowledge in language, math, and logic. Meanwhile, Fine-tuning is like an orientation week for a new employee (Intern). You only need a few days to teach this person - who already has a degree - how to write emails according to company standards or how to use internal software.
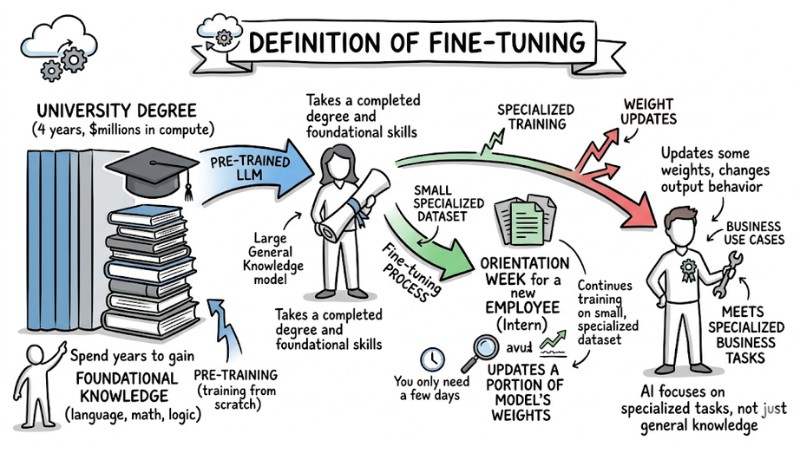
Fine-tuning is the process of taking a pre-trained Large Language Model
Why Not Train from Scratch?
Building an AI model from zero (Pre-training) requires supercomputing clusters with thousands of H100 GPUs running continuously for months, with costs reaching tens of millions of dollars. Fine-tuning solves this cost problem by inheriting 99% of the pre-structured neural network. You only spend a very small cost to "carve" the final 1% of neurons to fit your specific Use-case.
Technical Mechanisms Behind Fine-Tuning
The architecture of an AI model consists of many neural layers stacked on top of each other. In the Data Flow, data passes through the initial layers (Base layers) to recognize basic syntax and grammar, reaching the final layers (Task-specific layers) to decide response behavior and logic.
1. Freezing Weights
If you update all the Weights of a model during the refinement process, the system will encounter a serious error called catastrophic forgetting. This phenomenon occurs when the AI learns new knowledge but "forgets" how to use basic grammar or loses its original logical reasoning capability.
To prevent this, engineers use the Freeze Weights technique: locking all foundational neural layers and only allowing the gradient descent algorithm to update parameters in a few final layers.
2. Optimizing Costs with PEFT and LoRA
Previously, fine-tuning a 70-billion parameter model still required massive hardware. However, the emergence of PEFT (Parameter-Efficient Fine-Tuning) and especially the LoRA (Low-Rank Adaptation) technique has completely changed the game.
Instead of updating the giant network directly, LoRA inserts small matrices (Adapters) in parallel with the original layers. Thanks to this, the number of parameters needing training drops below 1%, allowing developers to run refinement smoothly even on consumer GPUs (like the RTX 4090) without degrading output performance.
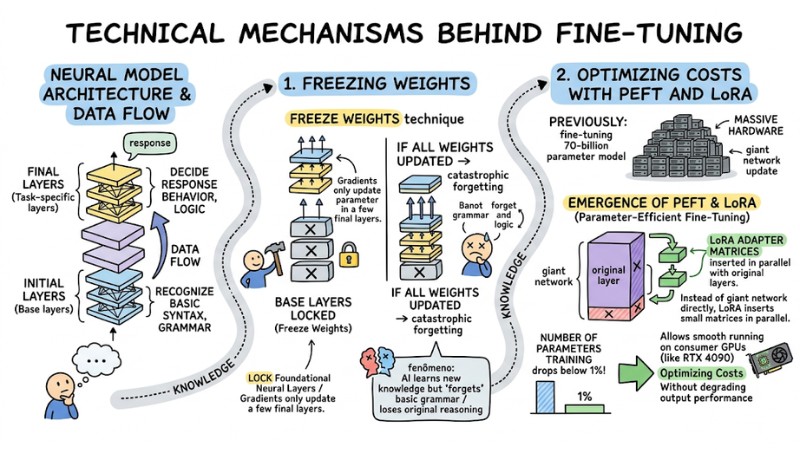
Technical Mechanisms Behind Fine-Tuning
Detailed Differentiation: Fine-tuning, RAG, and Prompt Engineering
A classic mistake costing many businesses today is: "Taking a pile of internal PDF documents and fine-tuning them in hopes that the AI will answer questions about company policy."
Regarding system nature:
- If you want the AI to know more new information (pricing policy, inventory) -> Use the. RAG technique (Retrieval-Augmented Generation).
- If you want the AI to change its way of speaking or processing behavior -> Use Fine-tuning.
| Criteria | Prompt Engineering | RAG Technique | Fine-Tuning |
|---|---|---|---|
| Main Purpose | Quick response steering. | Urgent internal data, new info. | Style change, strict formatting. |
| Implementation Cost | Very low ($0 - a few USD). | Medium (Vector DB & API fees). | High (Data prep & GPU rental). |
| Setup Time | Minutes - Hours. | Days - Weeks. | Weeks - Months. |
| Hallucination Risk | Very high without context. | Low (Clear source referencing). | Quite high (Prone to overfitting). |
To optimize costs and resources, Solution Architects usually apply the following logic:
- If you only need the AI to answer better, optimize Prompt Engineering first.
- If the AI needs to read internal documents, connect to Databases, or look up real-time prices, you absolutely must build a RAG system combined with a Vector DB.
- If RAG still answers in the wrong style, or you need the AI to output a very specific code format that prompts can't achieve, only then consider Fine-tuning.
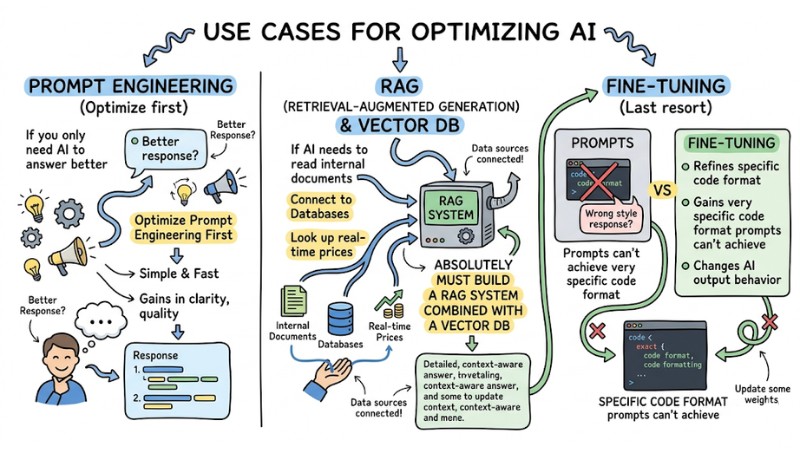
Use cases for Fine-tuning, RAG, and Prompt Engineering
Risks When Performing Fine-Tuning
Despite the professional accuracy benefits, the model refinement process carries infrastructure risks that Tech PMs need to include in budget estimates.
The Data Labeling Bottleneck
Many think the biggest cost of Fine-tuning is GPU rental. In reality, the personnel cost for cleaning and labeling the dataset is the true financial black hole.
According to the core principle of data science: "Garbage In, Garbage Out," if the JSONL file used for training contains logically incorrect or misspelled answers, the model will amplify that error many times over.
Overfitting Risk and Real-time Limits
Overfitting occurs when the dataset is too small or you train for too many cycles (Epochs). The model then becomes "obsessed" with the training data, answering sample questions excellently but becoming completely nonsensical (losing general reasoning ability) when encountering slightly different real-world situations.
Additionally, neural network weights after training are static. Therefore, you absolutely should not use this technique to teach the AI information that changes daily, such as stock prices, product inventory, or news events.
When Must an Enterprise Use Fine-Tuning?
Having understood the risks, here are 3 practical Use-cases worth investing your budget in for model refinement:
- Teaching AI to speak with a standard Brand Voice: Use Fine-Tuning when a Customer Support system needs to respond with an absolutely consistent tone/mood, using the brand's specific slang, etc. - something Prompt Engineering cannot stabilize when context becomes too long.
- Forcing Strict Output Formats: Most common in back-end systems. You refine a compact. LLM (like Llama 8B) so that 100% of the returned results are in a complex nested JSON/XML format, serving internal. API parsing without syntax errors.
- Learning Niche Industry Context: Applied in medicine (reading medical records), law (drafting contracts), or programming (coding with the company's internal framework). The AI needs to absorb terminology structures that the foundation model has never seen before.
Enterprise-scale AI application always requires a clear roadmap. Standard advice from systems engineers is: Exhaust the power of Prompt Engineering and RAG architecture before deciding to "burn money" on Fine-tuning.
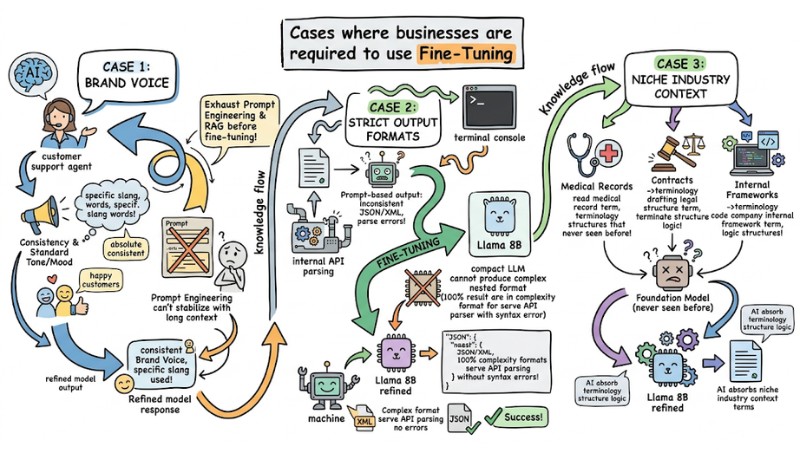
Cases where businesses are required to use Fine-Tuning
Frequently Asked Questions about Fine-tuning
What is Fine-tuning?
Fine-tuning (refinement) is the technique of adjusting the parameters of a pre-trained AI model on a specialized dataset. This process helps the model adapt better to specific tasks without needing to be trained from scratch.
How is Fine-tuning different from RAG?
Fine-tuning changes the behavior and response style of the model, while RAG provides external data for the model to look up. Choose Fine-tuning when you need to change the AI's "thinking," and choose RAG when you need to update real-time knowledge.
Should I Fine-tune an AI model for every problem?
No. You should only Fine-tune when you need to change a strict output format, strictly adhere to a Brand Voice, or work in a specialized field like Medicine or Law. For common information lookup needs, RAG is the optimal and more economical solution.
Why is Fine-tuning prone to Overfitting?
Overfitting occurs when a model is trained on a dataset that is too small or too narrow, causing it to lose general reasoning ability and become "rote-learning." This makes the model respond ineffectively when encountering questions or situations outside the dataset used for refinement.
What roles do PEFT and LoRA play in the refinement process?
PEFT (Parameter-Efficient Fine-Tuning) and LoRA are techniques that help minimize the number of parameters needing training (often under 1%), making Fine-tuning fast and consuming significantly fewer GPU resources compared to traditional full neural network refinement.
How to ensure security when Fine-tuning?
You should perform Fine-tuning directly on internal systems or private cloud environments to avoid leaking sensitive data. When deploying at scale, using platforms like GoClaw helps isolate workspaces, encrypt API keys, and manage strict authorization between. AI Agent teams.
Read more:
- What is Deep Learning? Applications, Future Trends, and Essential Knowledge
- Prompt Caching: How to Effectively Optimize LLM API Latency and Costs
- What Is an Orchestration Layer? Understanding Its Importance in System Architecture
In summary, fine-tuning is a powerful tool but not a "magic pill" for every AI problem in an enterprise. You should only invest in refinement when you have exploited the full potential of Prompt Engineering and RAG, and truly need a model with its own brand voice, specific output format, or deep understanding of a niche industry context to justify the data and infrastructure costs.