Fine-tuning là gì? Lợi ích, ứng dụng của việc tinh chỉnh AI

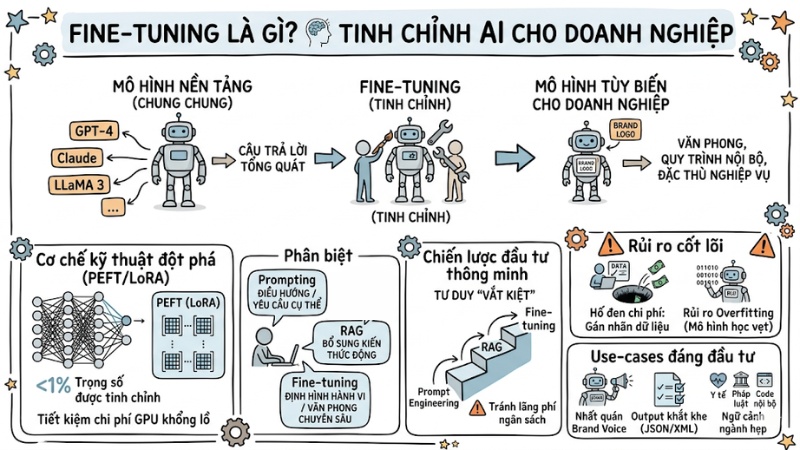
Fine-tuning là kỹ thuật tinh chỉnh một mô hình ngôn ngữ lớn (LLM) đã được huấn luyện sẵn để mô hình thích nghi với kiến thức và hành vi cho một bài toán doanh nghiệp cụ thể. Thay vì chấp nhận câu trả lời chung chung từ GPT-4, Claude hay LLaMA 3, bạn có thể biến mô hình nền tảng thành phiên bản tùy biến bám sát văn phong, quy trình và đặc thù nghiệp vụ nội bộ. Trong bài viết này, mình sẽ phân tích bản chất kỹ thuật, cơ chế hoạt động và đưa ra một framework giúp bạn quyết định khi nào nên (hoặc không nên) đầu tư fine-tuning để tránh lãng phí chi phí hạ tầng.
Những điểm chính
- Bản chất Fine-tuning: Hiểu rõ đây là kỹ thuật cho mô hình nền tảng, giúp tùy biến AI theo văn phong, quy trình và thuật ngữ riêng của doanh nghiệp thay vì phải xây dựng mô hình từ con số 0.
- Cơ chế kỹ thuật đột phá: Nắm vững vai trò của các kỹ thuật PEFT (như LoRA) trong việc chỉ tinh chỉnh <1% trọng số mô hình, giúp doanh nghiệp tiết kiệm chi phí tính toán GPU khổng lồ mà vẫn đạt hiệu quả chuyên biệt.
- Phân biệt Fine-tuning, RAG và Prompting: Xác định đúng bài toán: Dùng Prompt để điều hướng, RAG để bổ sung kiến thức động và Fine-tuning để định hình hành vi/văn phong chuyên sâu.
- Chiến lược đầu tư thông minh: Áp dụng tư duy "vắt kiệt" hiệu quả từ Prompt Engineering và RAG trước khi quyết định đầu tư vào Fine-tuning để tránh lãng phí ngân sách dữ liệu và hạ tầng.
- Rủi ro cốt lõi: Nhận diện "hố đen" chi phí từ khâu gán nhãn dữ liệu (Data Labeling) và rủi ro Overfitting (mô hình học vẹt, mất khả năng tư duy tổng quát) khi dữ liệu tinh chỉnh kém chất lượng.
- Use-cases đáng đầu tư: Chỉ định đúng 3 kịch bản thực tế cần Fine-tuning: Nhất quán Brand Voice, ép định dạng Output khắt khe (JSON/XML), và thẩm thấu ngữ cảnh ngành hẹp (Y tế, Pháp luật, Code nội bộ).
- Giải đáp FAQ: Làm rõ sự khác biệt giữa tinh chỉnh và truy xuất tri thức, cách sử dụng kỹ thuật LoRA để tối ưu tài nguyên và chiến lược đảm bảo bảo mật dữ liệu nhạy cảm trong quá trình tinh chỉnh.
Bản chất của Fine-Tuning là gì?
Định nghĩa Fine-Tuning
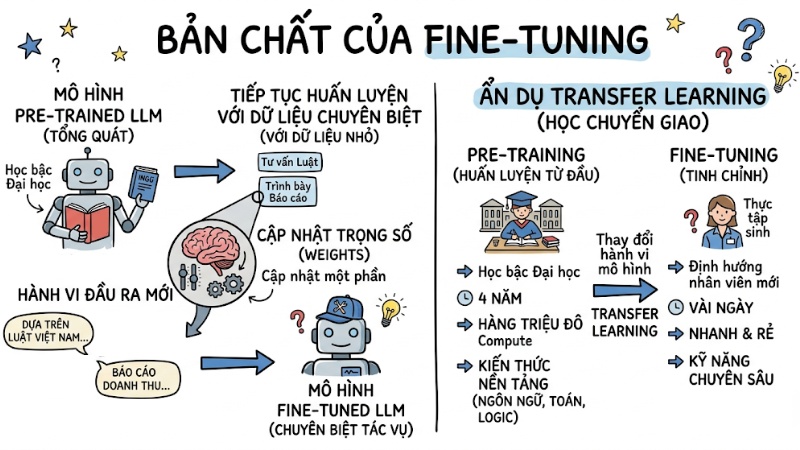
Fine-tuning (tinh chỉnh) là quá trình lấy một mô hình ngôn ngữ lớn đã được huấn luyện sẵn và tiếp tục huấn luyện nó trên một tập dữ liệu nhỏ, chuyên biệt. Cụ thể, kỹ thuật này cập nhật một phần trọng số (weights) của mô hình để thay đổi hành vi đầu ra. Điều này giúp AI đáp ứng chính xác các tác vụ nghiệp vụ chuyên sâu thay vì chỉ trả lời kiến thức tổng quát.
Để dễ hình dung, chúng ta có thể dùng một phép ẩn dụ về kỹ thuật Transfer Learning (Học chuyển giao). Cụ thể quá trình Pre-training (Huấn luyện từ đầu) giống như việc cho một người học hết bậc Đại học. Họ mất 4 năm (tiêu tốn hàng triệu đô la tiền compute) để có kiến thức nền tảng về ngôn ngữ, toán học, logic. Trong khi đó, Fine-tuning giống như tuần định hướng cho nhân viên mới (Thực tập sinh). Bạn chỉ cần mất vài ngày để dạy người đã có bằng Đại học này cách viết email theo đúng chuẩn của công ty hoặc cách dùng phần mềm nội bộ.
Bản chất của Fine-Tuning
Lý do không huấn luyện từ đầu
Việc tự xây dựng một mô hình AI từ con số không (Pre-training) đòi hỏi những cụm siêu máy tính với hàng ngàn card GPU H100 chạy liên tục trong nhiều tháng, đi kèm chi phí lên tới hàng chục triệu USD. Fine-tuning giải quyết bài toán chi phí (cost) này bằng cách kế thừa 99% mạng nơ-ron đã được cấu trúc sẵn. Bạn chỉ tốn chi phí rất nhỏ để "gọt giũa" lại 1% nơ-ron cuối cùng cho phù hợp với Use-case của mình.
Cơ chế kỹ thuật đằng sau quá trình Fine-tuning
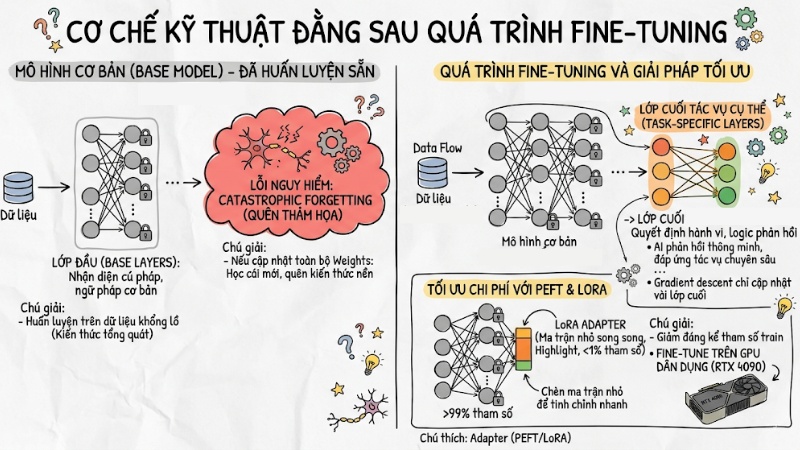
Kiến trúc của một mô hình AI bao gồm nhiều lớp nơ-ron (layer) xếp chồng lên nhau. Trong Data Flow, dữ liệu đi qua các lớp đầu (Base layers) để nhận diện cú pháp, ngữ pháp cơ bản và đi đến các lớp cuối (Task-specific layers) để quyết định hành vi, logic phản hồi.
1. Đóng băng trọng số
Nếu bạn cập nhật toàn bộ Weights (trọng số) của mô hình trong quá trình tinh chỉnh, hệ thống sẽ gặp phải một lỗi nghiêm trọng gọi là quên kiến thức cũ. Hiện tượng này xảy ra khi AI học kiến thức mới nhưng lại "quên" luôn cách sử dụng ngữ pháp cơ bản hoặc mất đi khả năng suy luận logic gốc.
Để ngăn chặn điều này, các kỹ sư sử dụng kỹ thuật Freeze Weights: Đóng băng toàn bộ các lớp nơ-ron cơ bản và chỉ cho phép thuật toán gradient descent cập nhật tham số ở một vài lớp cuối cùng.
2. Tối ưu chi phí với PEFT và LoRA
Trước đây, việc fine-tune một mô hình 70 tỷ tham số vẫn yêu cầu phần cứng cực lớn. Tuy nhiên, sự xuất hiện của PEFT (Parameter-Efficient Fine-Tuning - Tinh chỉnh hiệu quả tham số) và đặc biệt là kỹ thuật LoRA (Low-Rank Adaptation) đã thay đổi hoàn toàn cuộc chơi.
Thay vì cập nhật trực tiếp vào mạng lưới khổng lồ, LoRA chèn thêm các ma trận nhỏ (Adapter) song song với các lớp gốc. Nhờ đó, số lượng tham số cần train giảm xuống dưới 1%, cho phép các developer chạy tinh chỉnh mượt mà ngay trên các GPU dân dụng (như RTX 4090) mà không làm suy giảm hiệu năng đầu ra.
Cơ chế kỹ thuật đằng sau quá trình Fine-tuning
Phân biệt chi tiết Fine-tuning, RAG và Prompt Engineering
Một trong những sai lầm kinh điển gây tiêu tốn chi phí của phần lớn doanh nghiệp hiện nay là: "Cầm một mớ file PDF tài liệu nội bộ đi fine-tune với hy vọng AI sẽ trả lời được câu hỏi về chính sách công ty".
Về bản chất hệ thống:
- Nếu bạn muốn AI biết thêm thông tin mới (chính sách giá, tồn kho) -> Dùng kỹ thuật RAG (Truy xuất thông tin tăng cường).
- Nếu bạn muốn AI thay đổi cách nói chuyện, hành vi xử lý -> Dùng Fine-tuning.
| Tiêu chí | Prompt Engineering | Kỹ thuật RAG | Fine-Tuning |
|---|---|---|---|
| Mục đích chính | Điều hướng câu trả lời nhanh. | Cấp bách dữ liệu nội bộ, thông tin mới. | Đổi văn phong, ép chuẩn định dạng. |
| Chi phí triển khai | Rất thấp ($0 - Vài USD). | Trung bình (Tốn phí Vector DB & API). | Cao (Phí chuẩn bị Data & Thuê GPU). |
| Thời gian thiết lập | Vài phút - Vài giờ. | Vài ngày - Vài tuần. | Vài tuần - Vài tháng. |
| Rủi ro ảo giác (AI Hallucination) | Rất cao nếu thiếu context. | Thấp (Có source đối chiếu rõ ràng). | Khá cao (Dễ bị AI học vẹt - Overfitting). |
Để tối ưu chi phí và resource, các Solution Architect thường áp dụng luồng tư duy sau:
- Nếu bạn chỉ cần AI trả lời tốt hơn, hãy tối ưu hóa Prompt Engineering trước.
- Nếu AI cần đọc tài liệu nội bộ, kết nối Database, tra cứu giá realtime, bạn bắt buộc cần phải xây dựng hệ thống RAG kết hợp Vector DB.
- Nếu RAG vẫn trả lời sai văn phong, hoặc bạn cần AI xuất ra một định dạng code cực kỳ đặc thù mà prompt không làm nổi, bạn mới tính đến Fine-tuning.

Các trường hợp sử dụng Fine-tuning, RAG và Prompt Engineering
Những rủi ro khi thực hiện Fine-tuning
Bất chấp những lợi ích về độ chính xác chuyên môn, quá trình tinh chỉnh mô hình mang theo những rủi ro hạ tầng mà các Tech PM cần đưa vào bản dự toán ngân sách.
Nút thắt Data Labeling (Gán nhãn dữ liệu)
Nhiều người nghĩ chi phí lớn nhất của Fine-tuning là tiền thuê GPU. Thực tế, chi phí nhân sự cho việc làm sạch và gán nhãn dataset mới là hố đen tiêu tốn tiền thực sự.
Theo nguyên tắc cốt lõi của khoa học dữ liệu: "Garbage In, Garbage Out" (Dữ liệu rác tạo ra AI rác), nếu file JSONL dùng để train chứa các câu trả lời sai logic hoặc sai chính tả, mô hình sẽ khuếch đại lỗi đó lên gấp nhiều lần.
Rủi ro Overfitting và giới hạn Realtime
Overfitting (Học vẹt) xảy ra khi dataset quá nhỏ hoặc bạn train quá nhiều vòng (Epochs). Mô hình lúc này trở nên "ám ảnh" với dữ liệu huấn luyện, trả lời xuất sắc các câu hỏi mẫu nhưng hoàn toàn ngớ ngẩn (mất khả năng tư duy tổng quát) khi gặp tình huống thực tế hơi khác biệt.
Ngoài ra, các trọng số của mạng nơ-ron sau khi train là tĩnh (static). Do đó bạn tuyệt đối không nên dùng kỹ thuật này để dạy AI những thông tin thay đổi từng ngày như bảng giá cổ phiếu, tồn kho hàng hóa hay tin tức sự kiện.
Khi nào doanh nghiệp bắt buộc dùng Fine-Tuning?
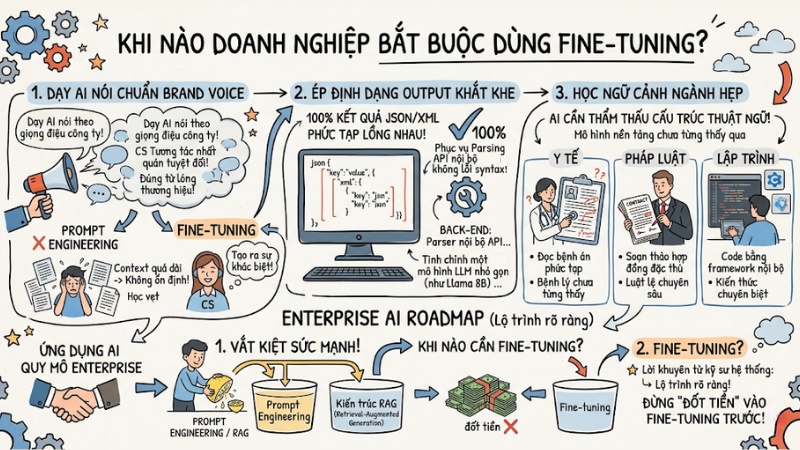
Khi đã hiểu rõ những rủi ro, đây là 3 use-cases thực tiễn đáng để bạn đầu tư ngân sách cho việc tinh chỉnh mô hình:
- Dạy AI nói chuẩn Brand Voice: Dùng Fine-Tuning khi hệ thống Customer Support cần trả lời theo một giọng điệu (tone/mood) nhất quán tuyệt đối, sử dụng đúng từ lóng của thương hiệu,… điều mà Prompt Engineering không thể duy trì độ ổn định khi context bị đẩy lên quá dài.
- Ép định dạng Output khắt khe: Phổ biến nhất ở các hệ thống back-end. Bạn tinh chỉnh một mô hình LLM nhỏ gọn (như Llama 8B) để 100% kết quả trả về là định dạng JSON/XML lồng nhau phức tạp, phục vụ việc parsing cho các API nội bộ mà không bị lỗi syntax.
- Học ngữ cảnh ngành hẹp: Áp dụng trong y tế (đọc bệnh án), pháp luật (soạn thảo hợp đồng) hoặc lập trình (code bằng framework nội bộ của công ty). AI cần thẩm thấu những cấu trúc thuật ngữ mà mô hình nền tảng chưa từng thấy qua.
Việc ứng dụng AI quy mô Enterprise luôn đòi hỏi một lộ trình rõ ràng. Lời khuyên chuẩn từ các kỹ sư hệ thống là: Hãy vắt kiệt sức mạnh của Prompt Engineering và kiến trúc RAG trước khi quyết định "đốt tiền" vào Fine-tuning.
Các trường hợp doanh nghiệp bắt buộc dùng Fine-Tuning
Câu hỏi thường gặp về Fine-tuning
Fine-tuning là gì?
Fine-tuning (tinh chỉnh) là kỹ thuật điều chỉnh các tham số của một mô hình AI đã được huấn luyện sẵn trên một tập dữ liệu chuyên biệt. Quá trình này giúp mô hình thích nghi tốt hơn với các nhiệm vụ đặc thù mà không cần huấn luyện lại từ đầu.
Fine-tuning khác gì so với RAG?
Fine-tuning thay đổi hành vi và phong cách phản hồi của mô hình, còn RAG cung cấp dữ liệu bên ngoài để mô hình tra cứu. Chọn Fine-tuning khi cần bạn thay đổi "tư duy" của AI, chọn RAG khi bạn cần cập nhật kiến thức thời gian thực.
Có nên Fine-tune mô hình AI cho mọi bài toán không?
Không. Bạn chỉ nên Fine-tune khi bạn cần thay đổi định dạng đầu ra khắt khe, tuân thủ nghiêm ngặt Brand Voice hoặc làm việc trong lĩnh vực đặc thù như Y tế, Pháp luật. Với các nhu cầu tra cứu thông tin thông thường, RAG là giải pháp tối ưu và tiết kiệm hơn.
Tại sao Fine-tuning dễ gặp rủi ro Overfitting?
Overfitting xảy ra khi mô hình được huấn luyện trên tập dữ liệu quá nhỏ hoặc quá hẹp, khiến nó mất khả năng tư duy tổng quát và trở nên "học vẹt". Điều này khiến mô hình phản hồi kém hiệu quả khi gặp các câu hỏi hoặc tình huống nằm ngoài tập dữ liệu đã dùng để tinh chỉnh.
PEFT và LoRA đóng vai trò gì trong quá trình tinh chỉnh?
PEFT (Parameter-Efficient Fine-Tuning) và LoRA là các kỹ thuật giúp giảm thiểu số lượng tham số cần huấn luyện (thường dưới 1%), giúp việc Fine-tuning trở nên nhanh chóng, tốn ít tài nguyên GPU hơn đáng kể so với việc tinh chỉnh toàn bộ mạng nơ-ron truyền thống.
Làm thế nào để đảm bảo tính bảo mật khi Fine-tuning?
Bạn nên thực hiện Fine-tuning trực tiếp trên hệ thống nội bộ hoặc môi trường private cloud để tránh rò rỉ dữ liệu nhạy cảm. Khi triển khai ở quy mô lớn, việc sử dụng các nền tảng như GoClaw giúp cách ly workspace, mã hóa API key và quản lý phân quyền chặt chẽ giữa các đội ngũ AI Agent.
Xem thêm:
- Deep Learning là gì? Phân tích kiến trúc và bản chất học sâu
- Prompt Caching: Cách tối ưu độ trễ và chi phí API LLM hiệu quả
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
Tóm lại, fine-tuning là công cụ mạnh nhưng không phải “thuốc tiên” cho mọi bài toán AI trong doanh nghiệp. Bạn chỉ nên đầu tư tinh chỉnh khi đã khai thác hết tiềm năng của Prompt Engineering và RAG, và thật sự cần một mô hình mang brand voice riêng, định dạng output đặc thù hoặc hiểu sâu ngữ cảnh ngành hẹp để xứng đáng với chi phí dữ liệu và hạ tầng bỏ ra.