What is Natural Language Processing (NLP)? Roles and Real-world Applications

Natural Language Processing (NLP) is one of the core foundations of modern artificial intelligence, where computers learn to read, understand, and respond in human language. It is a system of mathematical models and algorithms that help machines decode text, voice, and context across billions of data points. In this article, I will help developers, data engineers, and business managers clearly understand how NLP operates within an AI system, from raw language processing steps to creating intelligent responses that serve real-world problems.
Key Takeaways
- The Essence of NLP: Clearly understand that NLP is the bridge between the ambiguous world of human language and the rigid digital world (vector matrices) of computers.
- Language Processing Pipeline: Master the process from Tokenization, data cleaning, to redefining accurate vocabulary units for Vietnamese.
- Context Extraction: Know how computers utilize Deep Learning to overcome "keyword" traps (via attention weights), helping to accurately identify sarcastic or polysemous questions.
- Evolution of Architecture: Capture the turning point from scripted Chatbots to Transformer models and the era of AI Agents.
- Real-world Applications: Leverage NLP to decode unstructured data, automate business processes, and enhance intelligent decision-making capabilities within enterprises.
- FAQ Resolution: Understand why Vietnamese NLP is more difficult than English, the difference between Stemming/Lemmatization, and why modern AI Agent architecture is the inevitable replacement for old chatbots.
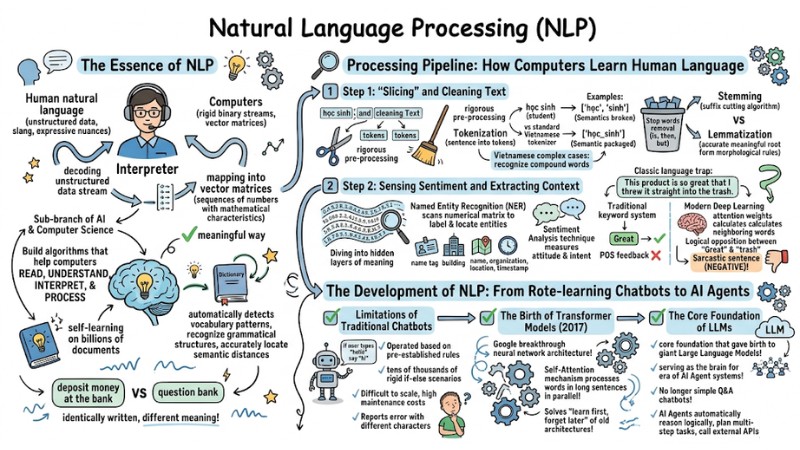
The Essence of NLP in Artificial Intelligence
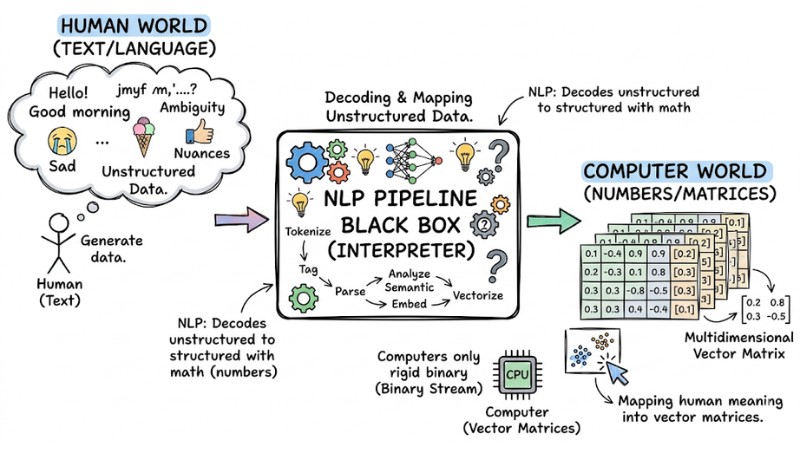
Natural Language Processing (NLP) is an important sub-branch of artificial intelligence (AI) and computer science, focusing on building algorithms that help computers read, understand, interpret, and process human natural language in a meaningful way.
To intuitively understand NLP in artificial intelligence, imagine this technology as a professional "interpreter" between two worlds. Computers are inherently only able to process rigid binary streams. Conversely, human language is unstructured data, containing ambiguity, slang, and expressive nuances. At this point, NLP performs the task of decoding this unstructured data stream, mapping them into vector matrices (sequences of numbers) with mathematical characteristics so that computers can perform calculations.
Thanks to Machine Learning models, current NLP systems do not merely look up dictionaries using string matching commands. Through a self-learning process on billions of documents, the machine automatically detects vocabulary distribution patterns, recognizes grammatical structures, and accurately locates semantic distances. This helps the computer understand that the word "bank" in the sentence "deposit money at the bank" is different from "bank" in "question bank," even though they are written identically.
The Essence of NLP in Artificial Intelligence
Processing Pipeline: How Computers Learn Human Language
The process of a computer processing basic language consists of the following steps:
Step 1: "Slicing" and Cleaning Text
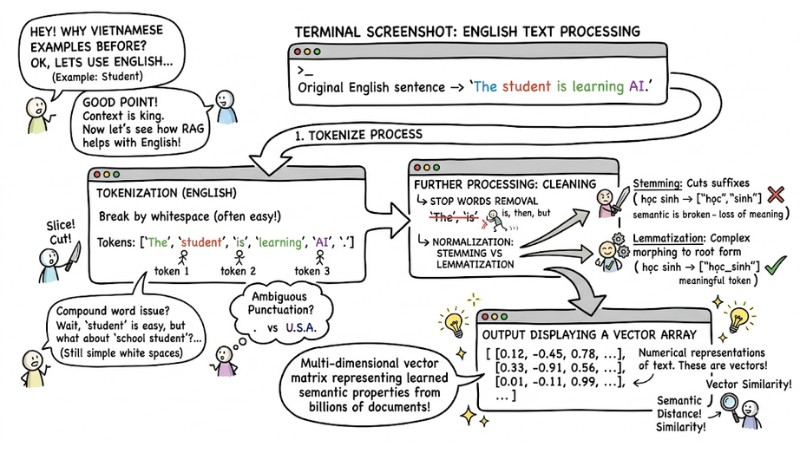
For a computer to process a long text, the data must undergo a rigorous pre-processing stage. The first foundational technique is Tokenization. This process divides a complete sentence into basic units called tokens.
Tokenization in English is usually easy because the system only needs to break based on whitespace (though there are still many complex cases due to abbreviations, compound words, and ambiguous punctuation usage). However, this becomes more complex when applied to Vietnamese.
Example: With the word "the student", if the system splits it into ["the", "student"], the semantics will be broken because two disjoint tokens are generated, losing the original meaning. A standard tokenizer needs to recognize compound words and package them into a single meaningful token, for example: ["the_student"].
After slicing, the system proceeds to remove meaningless words that carry no analytical value (Stop words removal) such as "is", "then", "but". Next, the algorithm will normalize the word forms. A clear distinction is needed: Stemming is an algorithm that cuts word suffixes, while Lemmatization is more complex, using morphological rule sets to bring a word back to its most accurate meaningful root form.
The data must undergo a rigorous pre-processing stage
Step 2: Sensing Sentiment and Extracting Context
Once the text has been converted into numerical vector sequences, the algorithm begins to dive into the hidden layers of meaning. The Named Entity Recognition (NER) technique scans the numerical matrix to label and locate entities such as names, organizations, locations, or timestamps.
More advanced, the Sentiment Analysis technique performs the task of measuring the attitude and intent of the writer. This is where language models demonstrate their difference in reasoning capability.
Consider a classic "language trap" left by a customer: "This product is so great that I threw it straight into the trash." Traditional keyword analysis systems might catch the word "great" and immediately misjudge this as positive feedback. However, modern Deep Learning architectures calculate the attention weights of neighboring words. They recognize the logical opposition between "great" and "throw in the trash," thereby accurately inferring that this is a sarcastic sentence (Negative).
The Development of NLP: From Rote-learning Chatbots to the Era of AI Agents
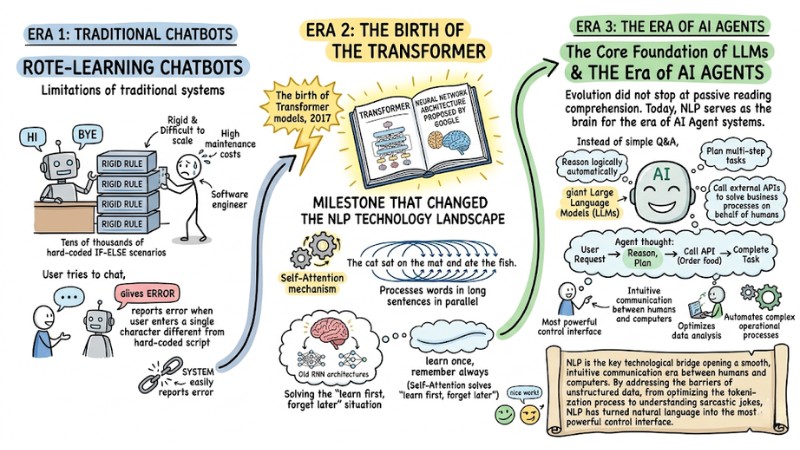
Limitations of Traditional Chatbots
In the previous stage, the application of NLP in modern enterprises was limited to Chatbot systems operated based on pre-established rules. Specifically, software engineers had to set up tens of thousands of rigid if-else scenarios. This limitation made the system difficult to scale, incurred high maintenance costs, and easily reported errors when a user entered a single character differently from the hard-coded script.
The Birth of Transformer Models
The milestone that changed the NLP technology landscape was the birth of Transformer models in 2017. This is not a piece of software, but a breakthrough neural network architecture proposed by Google. Through the Self-Attention mechanism, this model processes words in long sentences in parallel, solving the "learn first, forget later" situation of old architectures.
The Core Foundation of LLMs
This architecture is the core foundation that gave birth to giant Large Language Models (LLMs). Evolution did not stop at passive reading comprehension. Today, NLP serves as the brain for the era of AI Agent systems. No longer just simple Q&A chatbots, AI agents can now automatically reason logically, plan multi-step tasks, and call external APIs to solve business processes on behalf of humans.
In summary: NLP is the key technological bridge opening a smooth, intuitive communication era between humans and computers. By addressing the barriers of unstructured data, from optimizing the tokenization process to understanding sarcastic jokes, NLP has turned natural language into the most powerful control interface. Applying this technology not only helps optimize data analysis but also automates the complex operational processes of an organization.
The evolution of NLP: From rote-learning chatbots to the AI agent era
Frequently Asked Questions about NLP
What is NLP in information technology?
NLP (Natural Language Processing) is a branch of artificial intelligence that helps computers understand, interpret, and manipulate human natural language. It converts unstructured data (text, voice) into digital data so that the system can process it.
Why is Vietnamese Tokenization complex?
Vietnamese is an isolating language, where a word can consist of multiple syllables but only carries complete meaning when standing together (e.g., "học sinh"). For example, if the computer separates "học" and "sinh", the original meaning is lost, leading to misinterpreted information.
What is the difference between Stemming and Lemmatization?
Stemming is a technique that "cuts" suffixes to return a word to its root form, often fast but less accurate. Meanwhile, Lemmatization involves using morphological analysis to return a word to its standard dictionary form (lemma), helping the computer deeply understand the context and actual meaning of the word.
Why are modern AI Agent systems more effective than traditional Chatbots?
Traditional chatbots rely on rigid "If-else" rules, only responding according to available scripts. In contrast, AI Agents use Large Language Models (LLMs) to automatically reason, plan, and execute tasks more flexibly and intelligently in complex environments.
How to start deploying an AI Agent system for a business?
It is necessary to build a secure orchestration architecture, isolate data between users (multi-tenant), and support multi-model LLMs. You can also start by integrating automation processes into the GoClaw platform to manage agents safely and optimize costs.
Read more:
- What is MCP Transport? Understanding the Transmission Mechanisms of the Model Context Protocol
- What Is an Orchestration Layer? Understanding Its Importance in System Architecture
- What is no-code? Opportunities, risks, and when you should use it
In summary, Natural Language Processing is not just a sub-branch of artificial intelligence but the core infrastructure that helps computers “understand” humans, from words to deep context. By turning unstructured data into meaningful numerical representations, NLP paves the way for an era of AI Agents capable of reasoning, automating, and optimizing processes at an enterprise scale.