Natural Language Processing (NLP) là gì? Vai trò và ứng dụng thực tế

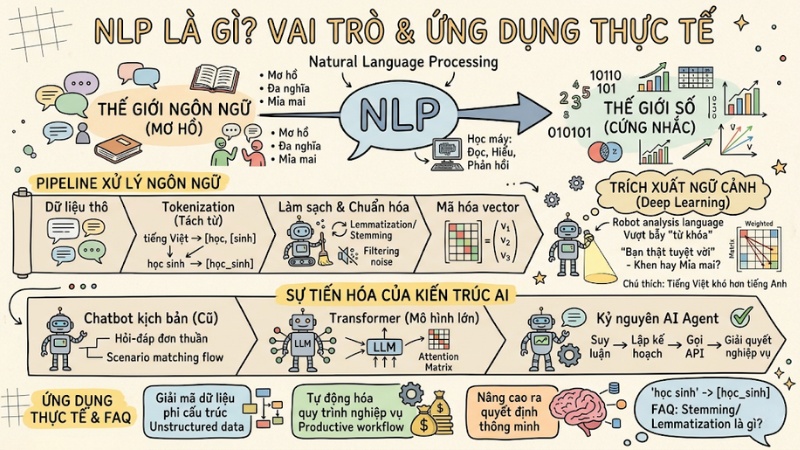
Natural Language Processing (NLP) là một trong những nền tảng cốt lõi của trí tuệ nhân tạo hiện đại, nơi máy tính học cách đọc, hiểu và phản hồi bằng ngôn ngữ con người. Đây là hệ thống các mô hình toán học và thuật toán giúp máy móc giải mã văn bản, giọng nói và ngữ cảnh ở quy mô hàng tỷ dữ liệu. Trong bài viết này, mình sẽ giúp các lập trình viên, kỹ sư dữ liệu và các nhà quản trị doanh nghiệp nắm rõ cách NLP vận hành bên trong hệ thống AI, từ bước xử lý ngôn ngữ thô đến việc tạo ra phản hồi thông minh phục vụ các bài toán thực tế.
Những điểm chính
- Bản chất của NLP: Hiểu rõ NLP là cầu nối giữa thế giới ngôn ngữ mơ hồ của con người và thế giới số (ma trận vector) cứng nhắc của máy tính.
- Pipeline xử lý ngôn ngữ: Nắm vững quy trình từ Tokenization (tách từ), làm sạch dữ liệu đến việc định nghĩa lại các đơn vị từ vựng chuẩn xác cho tiếng Việt.
- Trích xuất ngữ cảnh: Biết cách máy tính vận dụng Deep Learning để vượt qua bẫy "từ khóa" (thông qua trọng số attention), giúp nhận diện chính xác các câu hỏi mỉa mai hoặc đa nghĩa.
- Sự tiến hóa của kiến trúc: Nắm bắt bước ngoặt từ Chatbot kịch bản sang Transformer models và kỷ nguyên AI Agent.
- Ứng dụng thực tế: Tận dụng NLP để giải mã dữ liệu phi cấu trúc, tự động hóa quy trình nghiệp vụ và nâng cao năng lực ra quyết định thông minh trong doanh nghiệp.
- Giải đáp FAQ: Hiểu rõ tại sao NLP tiếng Việt khó hơn tiếng Anh, sự khác biệt giữa Stemming/Lemmatization, và tại sao kiến trúc AI Agent hiện đại là lựa chọn thay thế tất yếu cho chatbot cũ.
Bản chất của NLP trong trí tuệ nhân tạo
Natural Language Processing (NLP) là một phân nhánh quan trọng của trí tuệ nhân tạo (AI) và khoa học máy tính, tập trung vào việc xây dựng các thuật toán giúp máy tính đọc, hiểu, diễn giải và xử lý ngôn ngữ tự nhiên của con người một cách ý nghĩa.
Để hiểu trực quan NLP trong trí tuệ nhân tạo, hãy hình dung công nghệ này như một "thông dịch viên" chuyên nghiệp giữa hai thế giới. Máy tính vốn dĩ chỉ có thể xử lý luồng hệ nhị phân hoàn toàn cứng nhắc. Ngược lại, ngôn ngữ con người là dữ liệu phi cấu trúc, chứa sự mơ hồ, từ lóng và sắc thái biểu cảm. Lúc này, NLP sẽ làm nhiệm vụ giải mã luồng dữ liệu phi cấu trúc này, ánh xạ chúng thành các ma trận vector (chuỗi các con số) mang đặc trưng toán học để máy tính có thể tính toán.
Nhờ các mô hình Machine Learning (Học máy), hệ thống NLP hiện nay không chỉ đơn thuần tra cứu từ điển bằng các lệnh khớp chuỗi (string matching). Thông qua quá trình tự học trên hàng tỷ tài liệu, cỗ máy tự động phát hiện các quy luật phân bổ từ vựng, nhận diện cấu trúc ngữ pháp và định vị chính xác khoảng cách ngữ nghĩa. Điều này giúp máy tính hiểu rằng từ "ngân hàng" trong câu "gửi tiền ngân hàng" khác với "ngân hàng" trong "ngân hàng câu hỏi", dù chúng được viết giống hệt nhau.
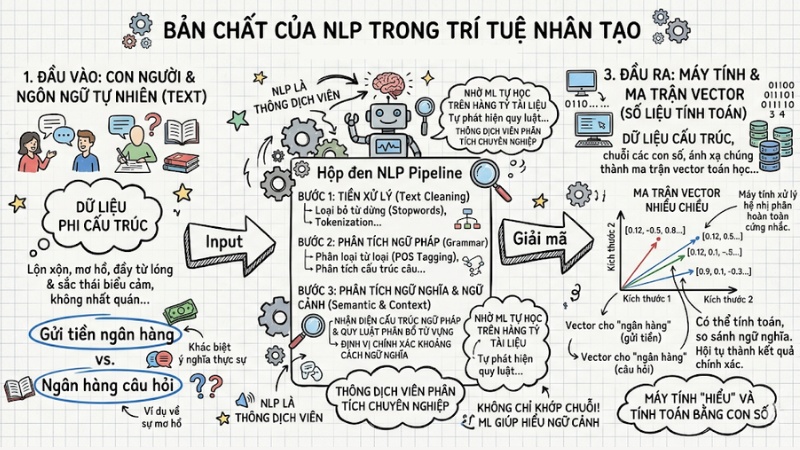
Bản chất của NLP trong trí tuệ nhân tạo
Pipeline xử lý” Máy tính học tiếng người như thế nào?
Quá trình máy tính xử lý ngôn ngữ cơ bản gồm các bước sau:
Bước 1: "Băm nhỏ" và làm sạch văn bản
Để máy tính có thể xử lý một văn bản dài, dữ liệu phải trải qua giai đoạn tiền xử lý nghiêm ngặt. Kỹ thuật nền tảng đầu tiên là Tokenization (Tách từ). Quá trình này chia một câu hoàn chỉnh thành các đơn vị cơ sở gọi là token.
Việc tách từ trong tiếng Anh thường dễ dàng vì hệ thống chỉ cần ngắt theo dấu khoảng trắng (vẫn có nhiều trường hợp phức tạp do chữ viết tắt, từ ghép và cách sử dụng dấu câu mơ hồ). Tuy nhiên, việc này trở nên phức tạp hơn khi áp dụng vào tiếng Việt.
Ví dụ: Với từ "học sinh", nếu hệ thống tách thành ["học", "sinh"], ngữ nghĩa sẽ bị phá vỡ vì sinh ra hai token rời rạc, mất đi ý nghĩa gốc. Một tokenizer tiếng Việt chuẩn cần nhận diện được từ ghép và đóng gói chúng thành một token duy nhất có nghĩa, ví dụ: ["học_sinh"].
Sau khi băm nhỏ, hệ thống tiến hành loại bỏ các từ vô nghĩa không mang giá trị phân tích (Stop words removal) như "là", "thì", "mà", "ở". Tiếp đó, thuật toán sẽ chuẩn hóa hình thái từ. Cần lưu ý sự phân định rõ ràng: Stemming là thuật toán cắt hậu tố của từ, còn Lemmatization phức tạp hơn, sử dụng bộ quy tắc hình thái học để đưa từ về dạng gốc có ý nghĩa chuẩn xác nhất.
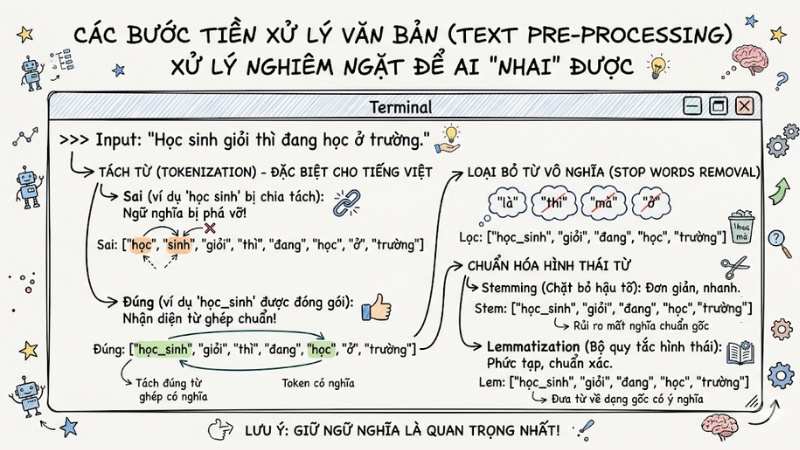
"Băm nhỏ" và làm sạch văn bản
Bước 2: Bắt mạch cảm xúc và trích xuất ngữ cảnh
Sau khi văn bản đã được chuyển thành các chuỗi vector số, thuật toán bắt đầu đi sâu vào lớp ý nghĩa ẩn. Kỹ thuật Named Entity Recognition (Nhận diện thực thể) rà quét ma trận số để gán nhãn và định vị các thực thể như tên riêng, tổ chức, địa điểm hoặc mốc thời gian.
Cao cấp hơn, kỹ thuật Sentiment Analysis (Phân tích cảm xúc) làm nhiệm vụ đo lường thái độ và ý đồ của người viết. Đây là nơi các mô hình ngôn ngữ thể hiện sự khác biệt về năng lực suy luận.
Hãy xét một "bẫy ngôn ngữ" kinh điển mà khách hàng để lại:"Sản phẩm này tuyệt đến mức tôi vứt thẳng vào thùng rác. Các hệ thống phân tích từ khóa truyền thống có thể bắt được từ "tuyệt" và ngay lập tức đánh giá sai lệch đây là phản hồi tích cực. Tuy nhiên, các kiến trúc học sâu (Deep Learning) hiện đại tính toán trọng số (attention) của các từ lân cận. Chúng nhận ra sự đối lập logic giữa "tuyệt" và "vứt thùng rác", từ đó suy luận chính xác đây là một câu mang sắc thái mỉa mai (Tiêu cực).
Sự phát triển của NLP: Từ Chatbot học vẹt đến kỷ nguyên AI Agent
Sự hạn chế của Chatbot truyền thống
Trong giai đoạn trước, ứng dụng của NLP trong doanh nghiệp hiện đại bị giới hạn ở các hệ thống Chatbot được vận hành dựa trên các quy luật được thiết lập sẵn. Cụ thể, kỹ sư phần mềm phải thiết lập hàng vạn kịch bản if-else cứng nhắc. Hạn chế này khiến hệ thống khó mở rộng, chi phí bảo trì cao và dễ dàng báo lỗi khi người dùng nhập sai một ký tự so với kịch bản được mã hóa cứng.
Sự ra đời của Transformer models
Cột mốc thay đổi cục diện công nghệ NLP là sự ra đời của Transformer models vào năm 2017. Đây không phải là một phần mềm, mà là một kiến trúc mạng nơ-ron đột phá do Google đề xuất. Thông qua cơ chế Self-Attention (Tự chú ý), mô hình này xử lý song song các từ trong câu dài, giải quyết tình trạng "học trước quên sau" của các kiến trúc cũ.
Nền tảng cốt lõi của LLM
Kiến trúc này là nền tảng cốt lõi khai sinh ra các Large Language Models (LLMs) khổng lồ. Sự tiến hóa không dừng lại ở việc đọc hiểu thụ động. Ngày nay, NLP đang làm bộ não cho kỷ nguyên của hệ thống AI Agent. Không còn là chatbot hỏi-đáp đơn thuần, các tác tử AI giờ đây có thể tự động suy luận logic, lập kế hoạch đa bước và gọi API ngoại vi để giải quyết quy trình nghiệp vụ thay con người.
Tóm lại: NLP là chìa khóa công nghệ then chốt mở ra kỷ nguyên giao tiếp mượt mà, trực quan giữa con người và máy tính.Bằng cách giải quyết rào cản của dữ liệu phi cấu trúc, từ tối ưu quá trình tách từ đến thấu hiểu câu đùa mỉa mai, NLP đã biến ngôn ngữ tự nhiên thành giao diện điều khiển mạnh mẽ nhất. Việc ứng dụng công nghệ này không chỉ giúp tối ưu hóa phân tích dữ liệu mà còn tự động hóa quy trình vận hành phức tạp của tổ chức.
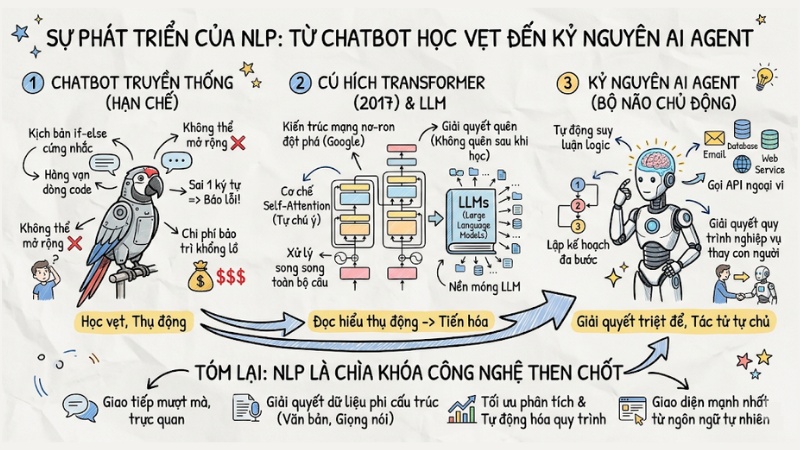
Sự phát triển của NLP: Từ Chatbot học vẹt đến kỷ nguyên AI Agent
Giải đáp các câu hỏi thường gặp về NLP
NLP là gì trong công nghệ thông tin?
NLP (Natural Language Processing) là một nhánh của trí tuệ nhân tạo, giúp máy tính hiểu, diễn giải và thao tác với ngôn ngữ tự nhiên của con người. Nó chuyển đổi dữ liệu phi cấu trúc (văn bản, giọng nói) thành dữ liệu số để hệ thống có thể xử lý.
Tại sao tách từ (Tokenization) tiếng Việt lại phức tạp?
Tiếng Việt là ngôn ngữ đơn lập, trong đó một từ có thể gồm nhiều âm tiết nhưng chỉ mang nghĩa trọn vẹn khi đứng cùng nhau (ví dụ: "học sinh"). Ví dụ, nếu máy tính tách lẻ "học" và "sinh", ngữ nghĩa gốc sẽ bị mất, dẫn đến hiểu sai thông tin.
Sự khác biệt giữa Stemming và Lemmatization là gì?
Stemming là kỹ thuật "cắt" hậu tố để đưa từ về dạng gốc, thường nhanh nhưng kém chính xác. Trong khi đó, Lemmatization là việc sử dụng phân tích hình thái học để đưa từ về dạng từ điển chuẩn (lemma), giúp máy tính hiểu sâu ngữ cảnh và ý nghĩa thực tế của từ ngữ.
Tại sao hệ thống AI Agent hiện đại hiệu quả hơn Chatbot truyền thống?
Chatbot truyền thống dựa trên quy tắc "If-else" cứng nhắc, chỉ phản hồi theo kịch bản có sẵn. Ngược lại, AI Agent sử dụng mô hình ngôn ngữ lớn (LLMs) để tự suy luận, lập kế hoạch và thực thi công việc linh hoạt, thông minh hơn trong môi trường phức tạp.
Làm thế nào để bắt đầu triển khai hệ thống AI Agent cho doanh nghiệp?
Cần xây dựng kiến trúc orchestration bảo mật, cách ly dữ liệu giữa người dùng (multi-tenant) và hỗ trợ đa mô hình LLM. Bạn cũng có thể bắt đầu bằng việc tích hợp quy trình tự động hóa vào nền tảng GoClaw để quản lý agent an toàn và tối ưu chi phí.
Xem thêm:
- MCP Transport là gì? Tìm hiểu cơ chế truyền tải của Model Context Protocol
- Orchestration Layer là gì? Tìm hiểu tầm quan trọng trong hệ thống
- No-code là gì? Cơ hội, rủi ro và trường hợp nên ứng dụng
Tóm lại, Natural Language Processing không chỉ là nhánh phụ của trí tuệ nhân tạo mà là hạ tầng cốt lõi giúp máy tính “hiểu” con người, từ câu chữ đến ngữ cảnh sâu xa. Bằng cách biến dữ liệu phi cấu trúc thành biểu diễn số có ý nghĩa, NLP mở đường cho kỷ nguyên AI Agent có khả năng suy luận, tự động hóa và tối ưu hóa quy trình ở quy mô doanh nghiệp.